Methodology
Local Model Bench tests whether local models can complete private, boring, failure-prone work: synthetic paperwork, messy folders, multi-step workflows, and one constrained visual output check.
Practical Score
For proof-style benchmarks, the public ranking uses 50% resolved pass rate and 50% core-oracle pass rate. This keeps exact completion important without treating a checksum miss like the same failure as a wrong invoice audit.
Common Checks
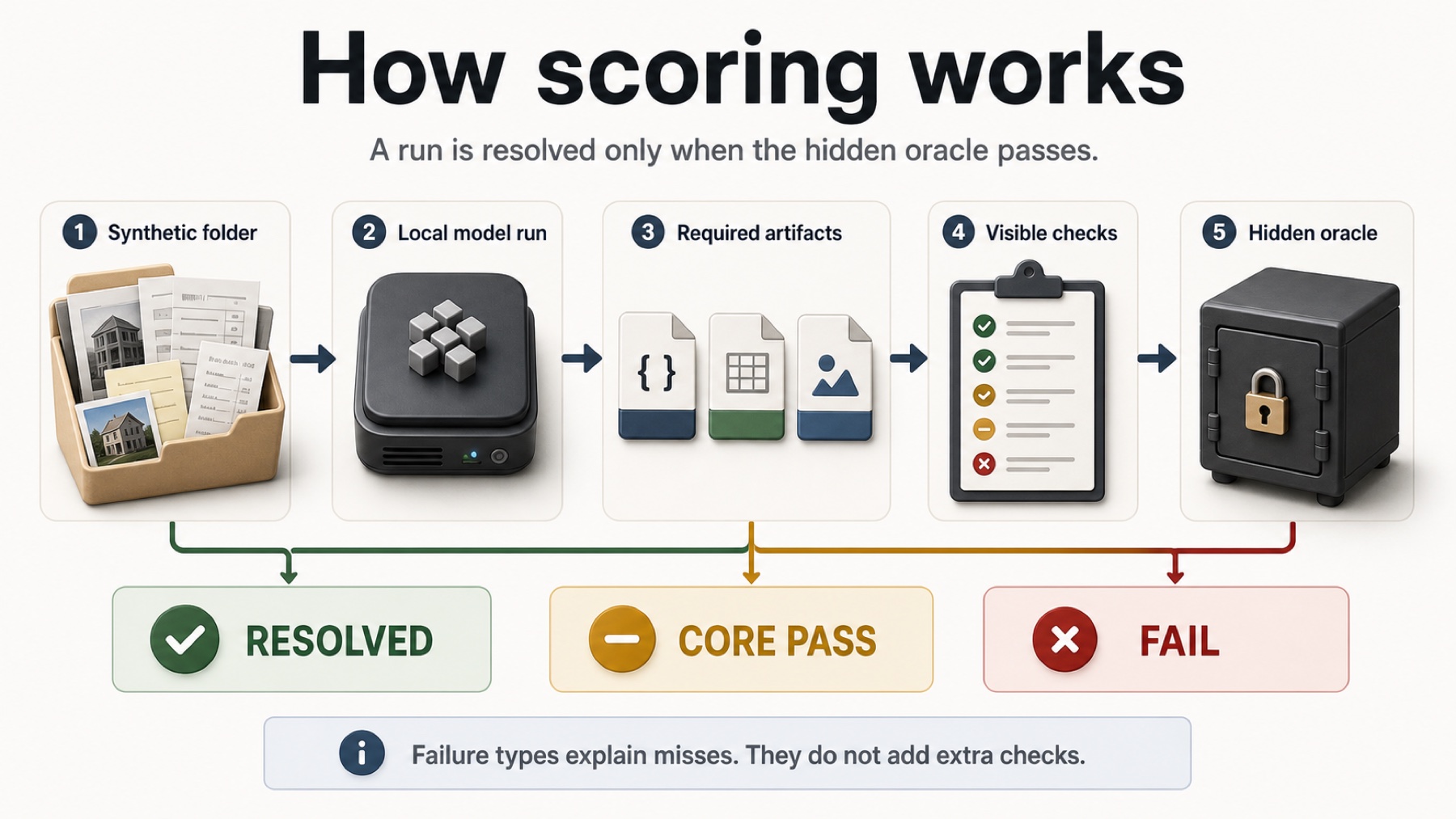
Common checks compare output existence, visible pass, core oracle pass, hidden oracle pass, and file protection where applicable. Failure types are separate diagnostic labels; they do not add extra failed checks to the score.
Benchmarks
The active site now focuses on the calibrated paperwork suite. The overall score combines scanned-paperwork cases and agentic paperwork workflows. City Plan SVG remains a separate visual sample.
Older exact-prompt, coding, and vision experiments are archived. They are not part of the current public score.
Ranking
Paperwork and paperwork workflow are ranked by Practical Score. The formula is simple: 0.5 × resolved_rate + 0.5 × core_rate.
Resolved means the case fully passes, including hidden oracle, proof code, final artifacts, and protected-source checks. Core means the central audit facts are correct, even if exact proof, evidence formatting, or normalized artifacts fail.
City Plan SVG is a single visual sample, not a percentage benchmark. It shows pass, review, or fail with the generated artifact and automated checks. If a model only writes planning text and no parseable SVG, the result is a fail.
Check score, visible checks, hidden-oracle passes, protected-file checks, and failure types remain visible as diagnostics and tie-breakers.
Hardware
Local LM Studio runs were executed on a Mac mini M4 with 64 GB unified memory.
Hardware is relevant for feasibility, runtime, and tokens-per-second comparisons. It does not change whether a task is marked resolved; reference/API rows are labeled separately because their inference does not run on this local machine.
Model Notes
Model Notes are commentary, not scoring. They summarize observed behavior from public runs: where a model resolved cases, where it only reached a core pass, and which failure patterns showed up repeatedly.
Notes do not change the leaderboard. They exist to make the raw scores less opaque and to document practical limits such as missed evidence paths, proof-code failures, wrong document selection, or incomplete workflow artifacts.
Paperwork
The Paperwork Trial uses synthetic document folders: generated invoice PNG scans, bank exports, vendor master files, purchase orders, previous invoices, and case rules. The model must produce an exact audit_result.json with status, warnings, evidence, ignored-document IDs, and a proof code.
The current generated-image suite has five cases with easy, medium, and hard traps: duplicate-risk lookup, partial payment, inactive-vendor, missing-PO, quote, credit-note, and purchase-order revision conflicts.
The current public v1 score combines those five generated-image cases with four agentic workflow cases. That is enough to compare local models without pretending to be a broad academic benchmark.
The data is fake by design. The benchmark is not financial, tax, or legal advice; it only tests whether a local model can follow a private-document workflow under objective checks.
Workflow
Workflow Trials test whether a local model can act like a useful desktop assistant: inspect a workspace, read instructions, copy assets, clean messy exports, generate manifests, and leave the original source files untouched.
The hidden oracle checks exact files and proof codes after the model finishes. This makes the benchmark less about sounding helpful and more about producing a verifiable local result.
City Plan SVG
City Plan SVG is the constrained visual sanity check. It asks for a standalone SVG containing roads or blocks, multiple buildings, and at least some 3D or isometric treatment. The point is constraint following, valid vector output, and a visible artifact people can inspect.
Because it is one prompt, the site does not present it as “100% vs 80%”. A pass means the automated constraints were met; visual quality still needs a human look. “No SVG output” means the model did not produce a parseable artifact.
What This Is Not
This is not a general intelligence score, not a replacement for large academic evals, and not a claim that one model is universally better than another.
It is a small practical test bench for local model behavior under reproducible settings, visible outputs, and deliberately ordinary work.