




88.9%Practical
5 miss types in details
The practical benchmark for local LLMs doing synthetic paperwork, messy local folders, hidden oracles, visible outputs, and one constrained City Plan SVG sanity check.
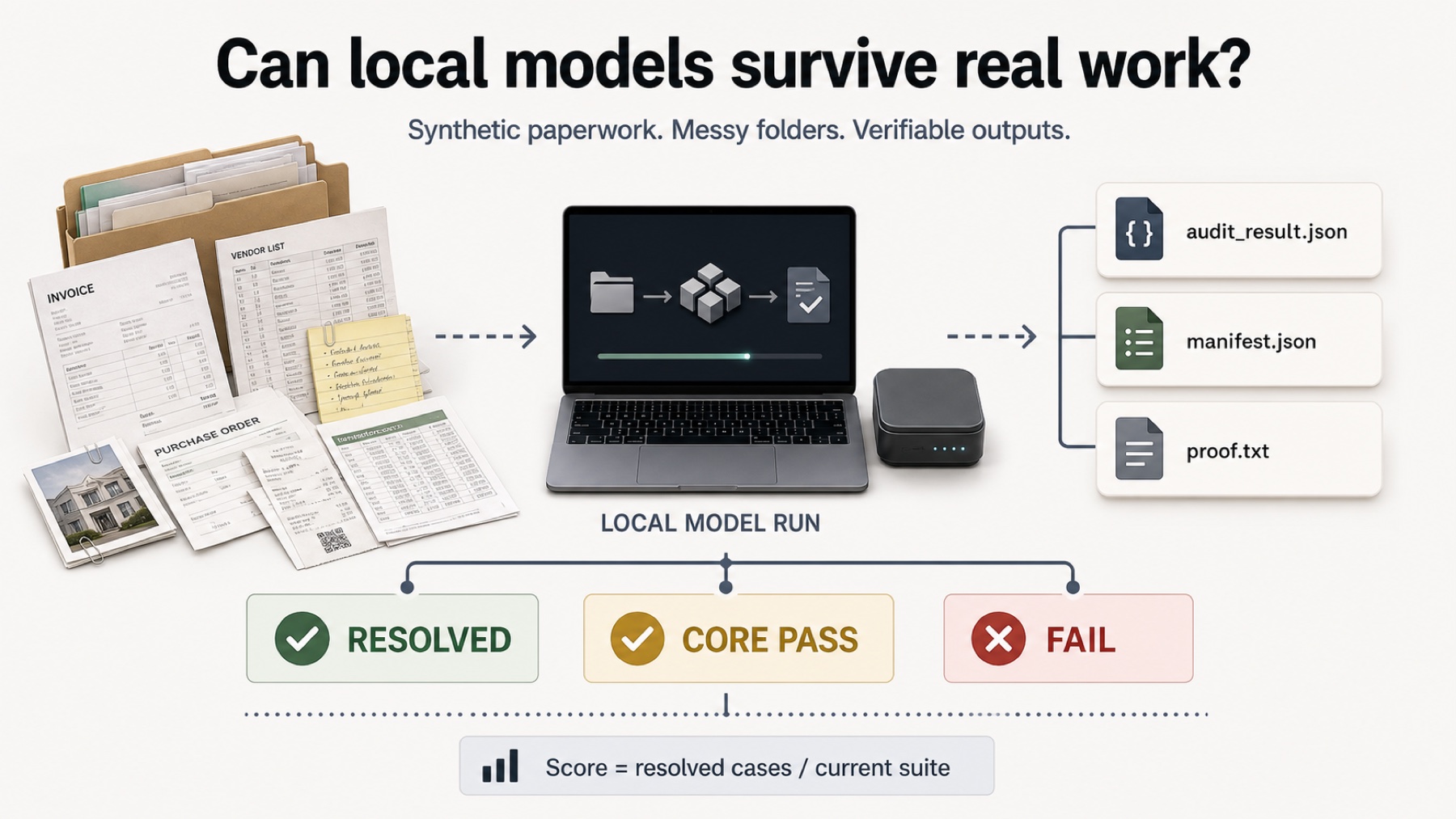
Synthetic invoice PNG scans plus bank exports, vendor records, purchase orders, and exact audit-result oracles.
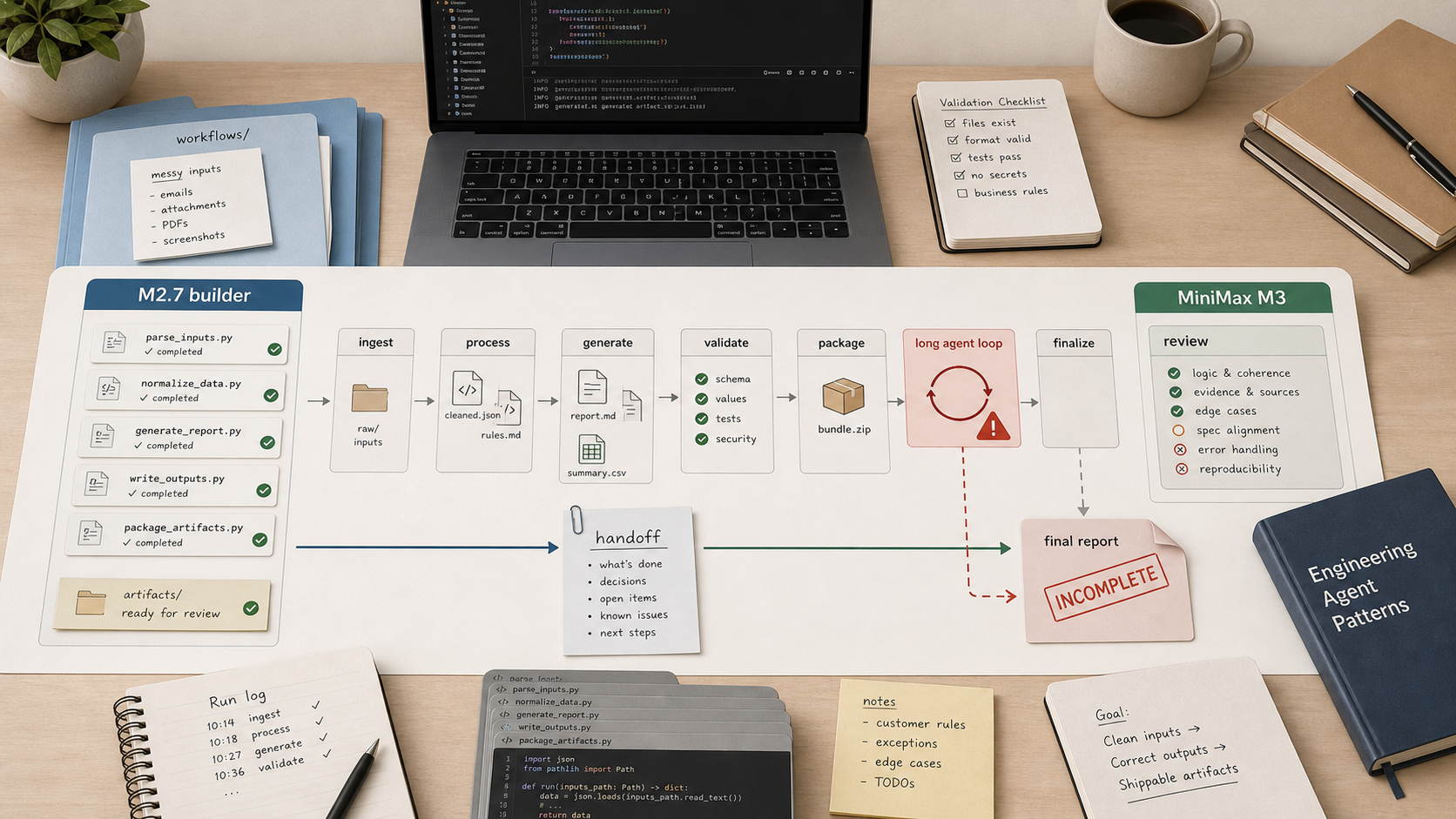
23 runs · 23 modelsscoredPaperwork WorkflowSynthetic messy intake and email-attachment workflows with generated scans, protected sources, normalized artifacts, payment remapping, and hidden oracles.
23 runs · 23 modelsdiagnosticPaperwork Text-OnlyThe same generated invoice cases, but with normalized text extracts instead of image input. This separates bookkeeping logic from document vision.
27 runs · shown as leaderboard modevisual sampleCity Plan SVGA city-plan SVG prompt with roads, blocks, and 3D or isometric buildings. Valid vector output, no Markdown excuses.
31 runs · not part of overall scoreA small visual sanity check: standalone SVG only, city blocks, roads, and 3D or isometric buildings.
Test reports that compare model positioning with observed benchmark behavior.
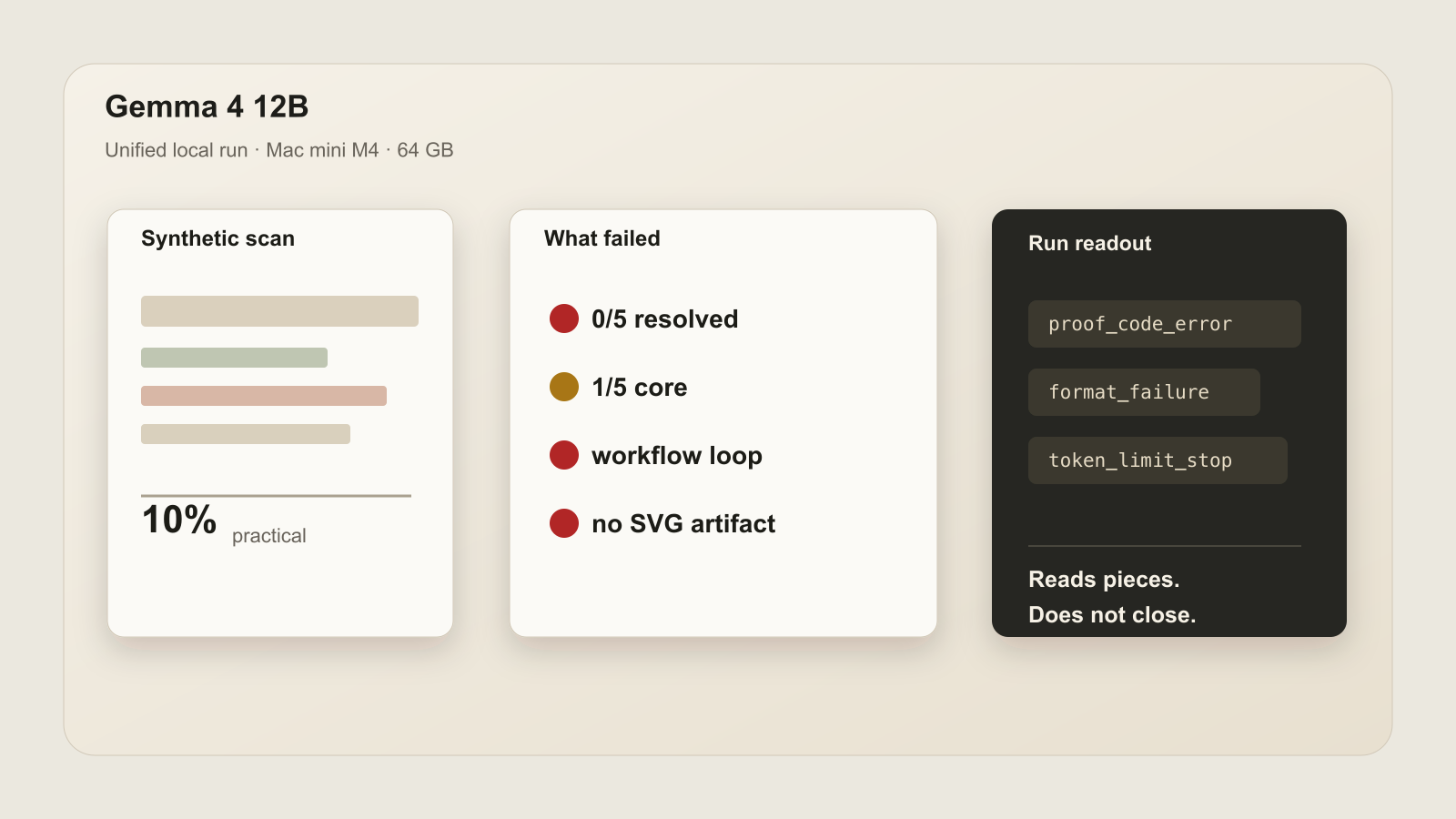
Top public comparison rows. Practical Score = 50% resolved cases + 50% core passes across the current v1 paperwork suite. Local LM Studio runs were executed on a Mac mini M4 with 64 GB unified memory.
Generated scans and messy workflow folders. This is the main public comparison score.
Same generated invoice cases, but with normalized text extracts instead of image input. Useful for separating bookkeeping logic from document vision.
10 of 23 shownSwipe sideways to see all columns.
| Rank | Model | Type | Practical | Resolved | Core | Tried | Case Matrix |
|---|---|---|---|---|---|---|---|
| 1 | opencode/minimax-m3-freedetails | api cheap | 88.9% | 8/9 | 8/9 | 9/9 | |
| 2 | OpenAI GPT-5.5 (Codex CLI)details | reference | 83.3% | 7/9 | 8/9 | 9/9 | |
| 3 | OpenAI GPT-5.4 Mini (Codex CLI)details | reference | 77.8% | 7/9 | 7/9 | 9/9 | |
| 4 | qwen3.6-27bdetails | local | 72.2% | 5/9 | 8/9 | 9/9 | |
| 5 | gemma-4-26b-a4bdetails | local | 61.1% | 4/9 | 7/9 | 9/9 | |
| 6 | qwen3.6-35b-a3bdetails | local | 38.9% | 1/9 | 6/9 | 9/9 | |
| 7 | qwen3.6-flashdetails | api cheap | 33.3% | 0/9 | 6/9 | 9/9 | |
| 8 | gemma-4-e4bdetails | local | 27.8% | 2/9 | 3/9 | 9/9 | |
| 9 | gemma-4-31b-itdetails | local | 27.8% | 0/9 | 5/9 | 9/9 | |
| 10 | gemini-3.1-flash-litedetails | api cheap | 27.8% | 0/9 | 5/9 | 9/9 | |
| 11 | gemini-2.5-flashdetails | api cheap | 27.8% | 0/9 | 5/9 | 9/9 | |
| 12 | Qwen3 VL 30B A3Bdetails | api cheap | 27.8% | 0/9 | 5/9 | 9/9 | |
| 13 | qwen3-vl-32b-instructdetails | api cheap | 22.2% | 0/9 | 4/9 | 9/9 | |
| 14 | Seed 2.0 Minidetails | api cheap | 22.2% | 0/9 | 4/9 | 9/9 | |
| 15 | Mistral Small 4details | api cheap | 22.2% | 0/9 | 4/9 | 9/9 | |
| 16 | mistral-small-3.2details | local | 16.7% | 0/9 | 3/9 | 9/9 | |
| 17 | ministral-3-14bdetails | local | 16.7% | 0/9 | 3/9 | 9/9 | |
| 18 | gemma-4-12bdetails | local | 5.6% | 0/9 | 1/9 | 9/9 | |
| 19 | gemma-4-e2bdetails | local | 0.0% | 0/9 | 0/9 | 9/9 | |
| 20 | qwen3-vl-8b-instructdetails | local | 0.0% | 0/9 | 0/9 | 9/9 | |
| 21 | qwen3-14bdetails | local | 0.0% | 0/9 | 0/9 | 9/9 | |
| 22 | nemotron-3-nano-omni-30b-a3b-reasoning:freedetails | api cheap | 0.0% | 0/9 | 0/9 | 9/9 | |
| 23 | ministral-3-3bdetails | local | 0.0% | 0/9 | 0/9 | 9/9 | |
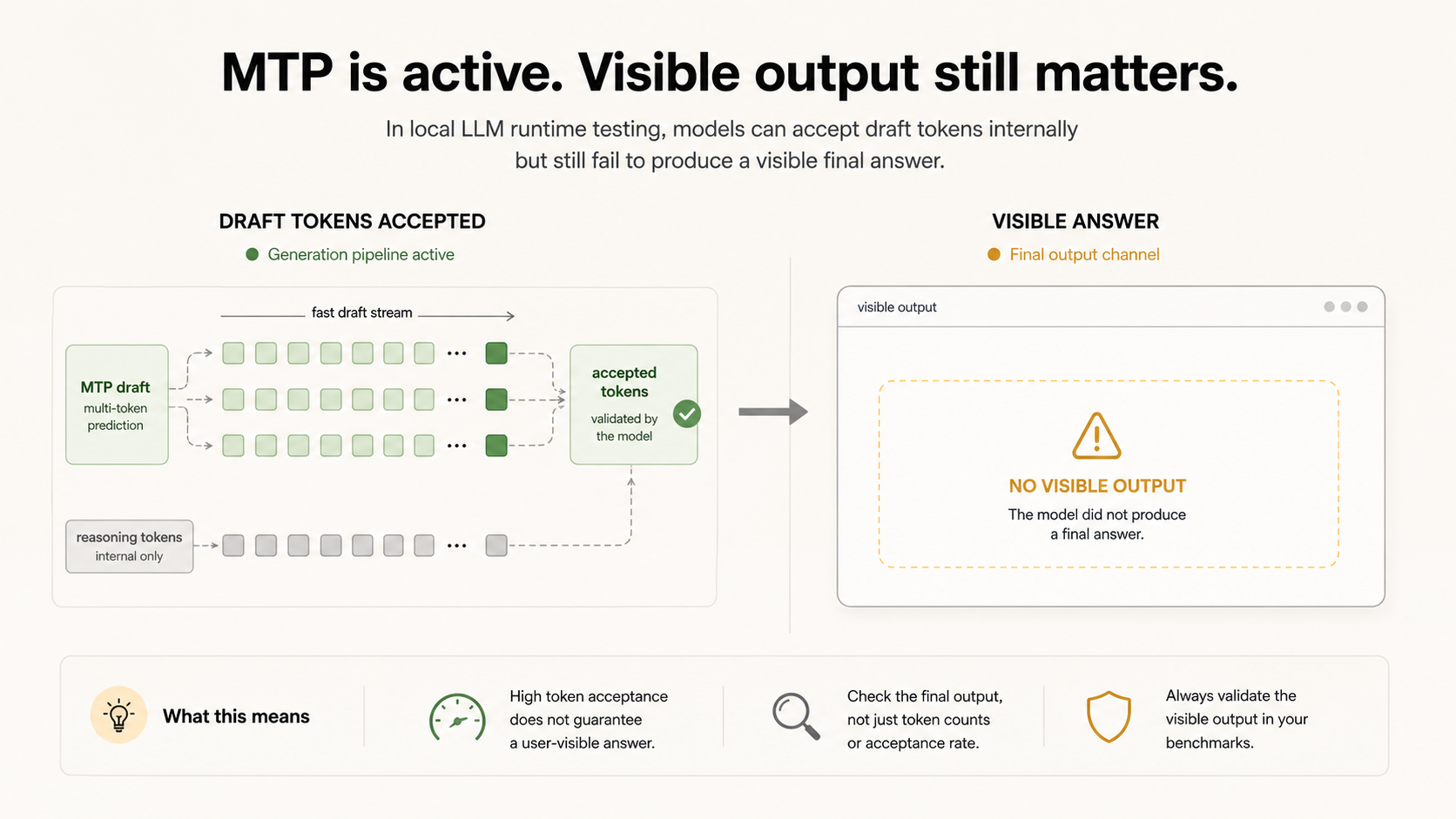
| 1 | qwen3.6-27b-mtpdetails | local | 100.0% | 5/5 | 5/5 | 5/5 | |
| 2 | qwen3.6-27bdetails | local | 90.0% | 4/5 | 5/5 | 5/5 | |
| 3 | qwen3.6-35b-a3bdetails | local | 80.0% | 4/5 | 4/5 | 5/5 | |
| 4 | gemma-4-26b-a4bdetails | local | 70.0% | 3/5 | 4/5 | 5/5 | |
| 5 | OpenAI GPT-5.5 (Codex CLI)details | reference | 60.0% | 2/5 | 4/5 | 5/5 | |
| 6 | OpenAI GPT-5.4 Mini (Codex CLI)details | reference | 60.0% | 3/5 | 3/5 | 5/5 | |
| 7 | gemma-4-e2bdetails | local | 60.0% | 3/5 | 3/5 | 5/5 | |
| 8 | gemini-3.5-flashdetails | local | 50.0% | 2/5 | 3/5 | 5/5 | |
| 9 | gemma-4-e4bdetails | local | 50.0% | 0/5 | 5/5 | 5/5 | |
| 10 | microsoft/phi-4-reasoning-plusdetails | local | 40.0% | 2/5 | 2/5 | 5/5 | |
| 11 | Qwen3.7 Maxdetails | api cheap | 40.0% | 0/5 | 4/5 | 5/5 | |
| 12 | gpt-oss-20bdetails | local | 30.0% | 0/5 | 3/5 | 5/5 | |
| 13 | ollama-gpt-oss-20bdetails | local | 30.0% | 0/5 | 3/5 | 5/5 | |
| 14 | gemma-4-31b-itdetails | local | 30.0% | 0/5 | 3/5 | 5/5 | |
| 15 | qwen3.6-flashdetails | api cheap | 20.0% | 0/5 | 2/5 | 5/5 | |
| 16 | Granite 4.1 8Bdetails | api cheap | 10.0% | 0/5 | 1/5 | 5/5 | |
| 17 | ollama-mistral-small-24bdetails | local | 10.0% | 0/5 | 1/5 | 5/5 | |
| 18 | ministral-3-14bdetails | local | 10.0% | 0/5 | 1/5 | 5/5 | |
| 19 | mistral-small-3.2details | local | 10.0% | 0/5 | 1/5 | 5/5 | |
| 20 | Chrome Gemini Nanodetails | browser | 10.0% | 0/5 | 1/5 | 5/5 | |
| 21 | Apple Foundation Modeldetails | system | 0.0% | 0/5 | 0/5 | 5/5 | |
| 22 | liquid/lfm2-24b-a2bdetails | local | 0.0% | 0/5 | 0/5 | 5/5 | |
| 23 | qwen3-vl-4bdetails | local | 0.0% | 0/5 | 0/5 | 5/5 | |
| 24 | qwen3-vl-8b-instructdetails | local | 0.0% | 0/5 | 0/5 | 5/5 | |
| 25 | qwen3-14bdetails | local | 0.0% | 0/5 | 0/5 | 5/5 | |
| 26 | gemma-3n-e4bdetails | local | 0.0% | 0/5 | 0/5 | 5/5 | |
| 27 | microsoft/phi-4details | local | 0.0% | 0/5 | 0/5 | 5/5 |
5 miss types in details
2 miss types in details
5 miss types in details
7 miss types in details
11 miss types in details
4 miss types in details
10 miss types in details
17 miss types in details
8 miss types in details
10 miss types in details
11 miss types in details
12 miss types in details
9 miss types in details
11 miss types in details
12 miss types in details
15 miss types in details
13 miss types in details
16 miss types in details
16 miss types in details
15 miss types in details
15 miss types in details
16 miss types in details
14 miss types in details
no main misses
1 miss types in details
3 miss types in details
6 miss types in details
2 miss types in details
3 miss types in details
8 miss types in details
4 miss types in details
2 miss types in details
3 miss types in details
6 miss types in details
6 miss types in details
4 miss types in details
5 miss types in details
6 miss types in details
6 miss types in details
6 miss types in details
6 miss types in details
7 miss types in details
8 miss types in details
8 miss types in details
6 miss types in details
6 miss types in details
7 miss types in details
7 miss types in details
7 miss types in details
1 miss types in details