What changed in LM Studio
LM Studio's 0.4.14 changelog says MTP speculative decoding is now stable and should speed up generation for models that include built-in multi-token prediction heads. The same release also fixed `lms get gemma4`, which is useful housekeeping because Gemma 4 is one of the families people are watching on Apple Silicon.
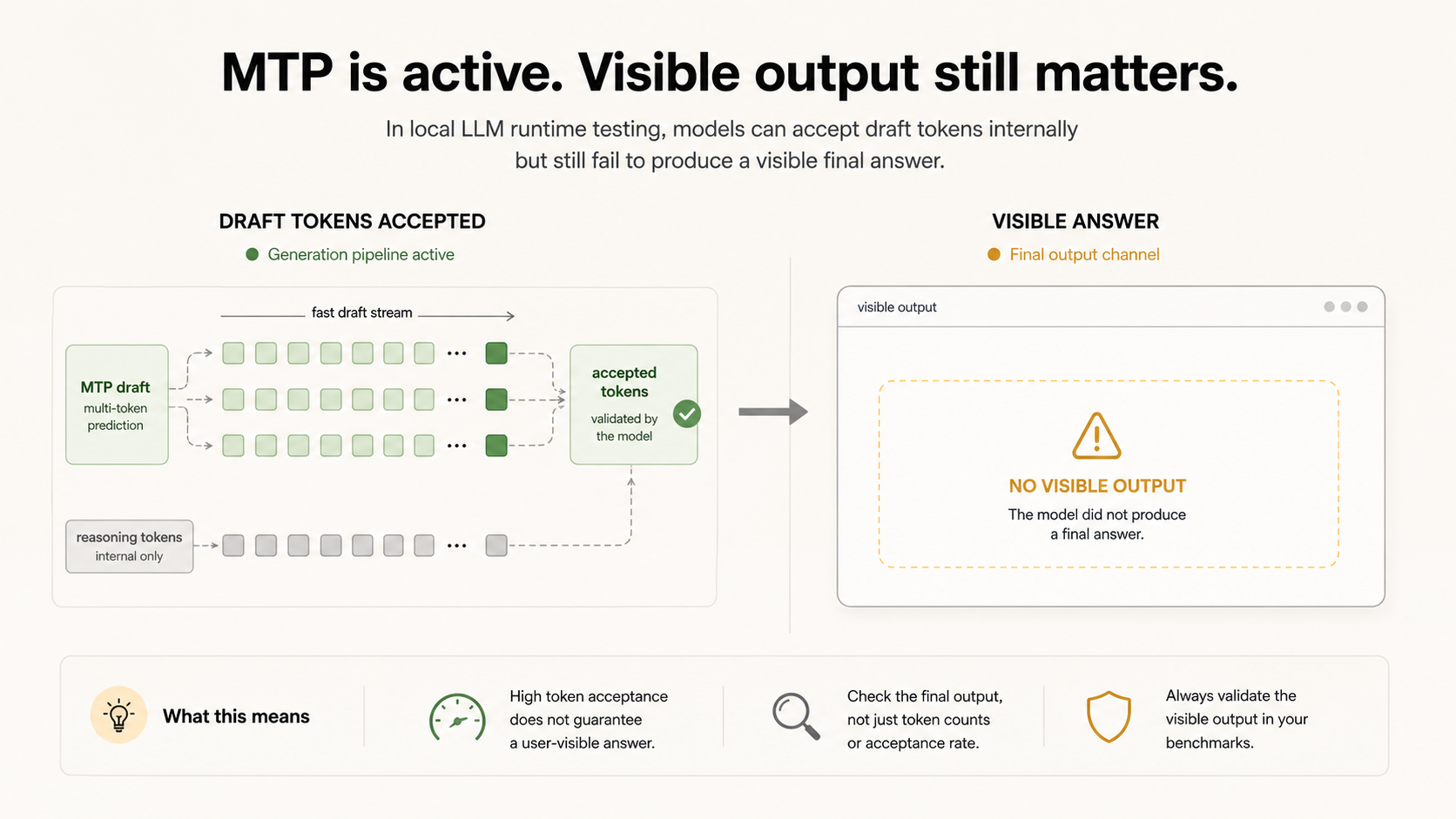
MTP is not a new reasoning skill. It is a decoding path. The runtime drafts multiple future tokens, then the target model verifies them. If the draft tokens match what the target would have generated anyway, the runtime can move faster.
That last sentence is the trap. Token throughput can improve while task reliability stays exactly where it was. If the model writes the wrong file, fails JSON, or spends the output budget thinking, the faster decoder did not solve the user's problem.
What others are seeing
The outside signal is positive, but messy.
OptIQ reports a 1.40x speedup for Qwen3.6 27B with an MTP head on Apple Silicon under its published OptIQ 4-bit greedy-decoding setup. The same page reports a smaller 1.18x geomean speedup for Gemma 4 E4B with an assistant drafter.
vLLM documents MTP as a speculative-decoding method for models that natively support it, and treats Gemma 4 assistant checkpoints as a special MTP path rather than generic draft models.
Reddit reports are noisier. Some users report modest LM Studio gains, such as roughly 7.67 tok/s versus 6.77 tok/s or 10.75 versus 9.02 on Qwen3.6 MTP variants. Others report much larger gains in different runtimes or hardware setups, and one comparison says optimized llama-server was far faster than LM Studio on the same general model family.
The newest community attention is around Qwen3.6 27B MTP under vLLM and llama.cpp. Some reports show very high throughput on RTX 5090-class hardware, often with NVFP4 quantization and large-context setups. That is interesting, but it is not the same thing as a Mac mini desktop workflow.
That range matters more than the headline. MTP is not one number. It depends on model, quant, context, sampler, runtime, hardware, whether the feature is actually enabled, and whether the generated tokens become useful final output.
What we tested locally
We ran a small local probe on a Mac mini M4 with 64 GB unified memory through LM Studio's OpenAI-compatible API.
The tested runtime stack was the current LM Studio MLX path reported locally as `mlx-engine==b229b95`, `mlx==0.31.2`, `mlx-lm==0.31.3`, and `mlx-vlm==0.4.5`.
The probe used three small tasks: JSON extraction, a proof-code calculation, and a tiny CSV artifact. This was not a leaderboard run. It was a runtime sanity check: does the model return visible output, how long does it take, and does MTP behave differently from the normal Qwen3.6 27B build?
- Runtime: LM Studio MLX stack, OpenAI-compatible local API
- Hardware: Mac mini M4, 64 GB unified memory
- MTP model: qwen3.6-27b-mtp
- Control model: qwen/qwen3.6-27b
- Additional comparison: google/gemma-4-26b-a4b
- Prompt type: short visible-output artifacts
- Temperature: 0, top_p: 1
The speed result
On the 500-token local probe, Qwen3.6 27B MTP averaged about 10.09 output tokens per second and 45.81 seconds per prompt. The non-MTP Qwen3.6 27B build averaged about 9.02 tokens per second and 55.70 seconds per prompt.
That is a real improvement, but not a dramatic one here. It looks closer to the modest community reports than to the best-case headline numbers.
Gemma 4 26B-A4B was much faster on the tiny probe at about 33.8 tokens per second. That does not make it better at the full benchmark by itself. It does show why runtime speed and task resolution need separate columns.
- Qwen3.6 27B MTP: about 10.09 tok/s, 45.81s average elapsed
- Qwen3.6 27B non-MTP: about 9.02 tok/s, 55.70s average elapsed
- Gemma 4 26B-A4B: about 33.8 tok/s, 10.34s average elapsed
- MTP advantage over non-MTP Qwen in this probe: visible, but small
The llama.cpp check was configuration-sensitive
After that, we upgraded local llama.cpp from build 8670 to 9430 because the older server did not expose native MTP controls. The newer server did: it accepted `--spec-type draft-mtp` and logged `speculative implementation 'draft-mtp'`.
That confirms the important part: this was not just a label in a UI. llama.cpp actually initialized a draft-MTP context for the same Qwen3.6 27B Q4_K_S GGUF.
The first run used auto parallelism and `n_max=3`. That was worse: about 9.62 tokens per second without MTP versus about 8.05 with draft-MTP. After checking current Qwen3.6 guidance, we reran the same probe with `-np 1`, `--no-mmproj`, and `--spec-draft-n-max 2`.
That version behaved better. No-MTP averaged about 10.33 wall-clock output tokens per second. draft-MTP averaged about 10.55. The server logs showed draft acceptance around 81-90% on the tuned run.
So the fair read is not 'llama.cpp MTP is slower.' The fair read is narrower: on this Mac mini, this quant, this context, and this short artifact-style workload, native MTP worked but only produced a very small gain after using the right flags.
- llama.cpp before upgrade: build 8670, no draft-mtp option visible
- llama.cpp after upgrade: build 9430, `--spec-type draft-mtp` available
- Model file: Qwen3.6-27B-Q4_K_S.gguf from the local Qwen3.6 MTP GGUF folder
- Auto-parallel no-MTP probe: about 9.62 tok/s, 48.88s average elapsed
- Auto-parallel draft-MTP `n_max=3`: about 8.05 tok/s, 58.41s average elapsed
- Single-stream no-MTP probe: about 10.33 tok/s, 45.46s average elapsed
- Single-stream draft-MTP `n_max=2`: about 10.55 tok/s, 44.58s average elapsed
- Observed tuned-run draft acceptance in server logs: roughly 81-90%
Where the answer disappeared
The question was not whether MTP engaged. It did. The API responses exposed draft-token statistics and `reasoning_content`.
The problem was the answer channel. With an 80-token limit on a trivial `2+2` prompt, the response returned no visible content and stopped at the length limit. With a 500-token limit, the model finally returned `4`, but only after 193 reasoning tokens.
The same pattern showed up in the tiny runtime probe. Qwen3.6 MTP completed the API requests, but two of three 500-token probe answers ended with empty visible output because the budget went into reasoning. The non-MTP Qwen build was worse: three of three were empty at the same limit.
For chat this is annoying. For a benchmark that asks for JSON, CSV, SVG, or a final file, it is fatal. The artifact is there, or it is not.
- Direct 2+2 check at 80 tokens: no visible answer, `finish_reason=length`
- Direct 2+2 check at 500 tokens: visible `4`, but 193 reasoning tokens
- Qwen3.6 MTP 500-token probe: 2 of 3 visible outputs empty
- Qwen3.6 non-MTP 500-token probe: 3 of 3 visible outputs empty
The paperwork test was the reality check
After the tiny probe, we tried one real Local Model Bench case: `generated_invoice_case_01` from the Paperwork Trial. Same local API path, Qwen3.6 27B MTP, 7,000 output tokens, roughly six minutes before the client timeout.
It timed out.
I am not counting that as a formal leaderboard failure because it was not a full calibrated suite run. But it is still a useful result. A speed feature can be real and still not make the model usable for the actual folder.
- Case tried: generated_invoice_case_01
- Model: qwen3.6-27b-mtp
- Output budget: 7,000 tokens
- Client timeout: about six minutes
- Result: no scored artifact, timeout
The first text-only rerun exposed the budget problem
To separate image reading from runtime behavior, we also tried the text-only version of the same generated-invoice case. No scans. The model received the normalized document extracts and CSV context, then had to return `audit_result.json` as JSON only.
At a 2,400-token output budget, LM Studio and llama.cpp failed in the same shape. Both ran until the length limit. Both returned zero visible output. LM Studio reported 2,399 reasoning tokens out of 2,400 completion tokens. llama.cpp also ended at the length limit with an empty content field.
That did not prove the model could not solve the case. It proved something narrower and more operational: at that budget, the model did not get to the artifact.
- Task: Paperwork v3 text-only generated_invoice_case_01
- LM Studio Qwen3.6 MTP: 238.7s, 2,400 completion tokens, 2,399 reasoning tokens, no JSON
- llama.cpp Qwen3.6 MTP: 224.3s, 2,400 completion tokens, no visible content, no JSON
- Both runs ended with `finish_reason=length`
- Both runs produced no `audit_result.json`
A higher budget changed the result
Then we reran the same LM Studio text-only case with a 7,000-token output budget. This time the model produced an `audit_result.json`, and the verifier passed it: strict oracle pass and core pass.
The catch is the path it took. The run lasted 361.1 seconds. The response used 3,896 completion tokens, of which 3,714 were reasoning tokens. The visible JSON was only 520 characters.
So the honest conclusion changes. Qwen3.6 MTP was not unable to solve the text-only case. It solved it after being given enough room to think. For Local Model Bench, that means budget discipline has to become part of the runtime story.
- Same case: Paperwork v3 text-only generated_invoice_case_01
- Backend: LM Studio Qwen3.6 MTP
- Output budget: 7,000 tokens
- Elapsed: 361.1s
- Completion tokens: 3,896
- Reasoning tokens: 3,714
- Visible JSON: 520 characters
- Verifier: strict pass and core pass
The real benchmark run was close
After the budget check, we ran the five generated-invoice text-only cases as a direct LM Studio comparison: `qwen3.6-27b-mtp` versus `qwen/qwen3.6-27b`, both with a 12,000-token output budget.
MTP won on strict closure. It solved all five cases. The non-MTP build reached core pass on all five, but missed the strict oracle on Case 03 because the proof code was wrong.
On cost, the result was much less dramatic. MTP used 23,497 completion tokens and 22,395 reasoning tokens. Non-MTP used 23,937 completion tokens and 22,835 reasoning tokens. MTP was also only slightly faster across the five cases: about 2,182 seconds total versus about 2,213 seconds.
That is the useful readout: MTP helped a little, and may have helped strict closure on the hardest case. It did not turn Qwen3.6 into a fast paperwork engine.
- Suite: five Paperwork v3 generated-invoice text-only cases
- Budget: 12,000 output tokens per case
- MTP strict result: 5/5
- Non-MTP strict result: 4/5
- MTP core result: 5/5
- Non-MTP core result: 5/5
- MTP total elapsed: about 2,182s
- Non-MTP total elapsed: about 2,213s
- MTP reasoning tokens: 22,395
- Non-MTP reasoning tokens: 22,835
- Non-MTP miss: Case 03 proof_code_error
Why this is not surprising
This is not just a Local Model Bench gripe.
A recent paper on speculative decoding makes the same general point in a more formal way: real-world speedups are not as settled as the clean theory suggests. Verification cost, acceptance length, workload shape, and serving details all matter.
That fits what happened here. The runtime can draft and accept tokens, but the user only benefits if those tokens turn into the thing they asked for. A predictable continuation may benefit. A document workflow that burns hundreds or thousands of reasoning tokens before writing the artifact may not.
Readout
The fair version is this: Qwen3.6 MTP is real. LM Studio's path gave us a small local speed gain over the non-MTP Qwen build, and llama.cpp produced a tiny gain after tuning the flags.
The practical version is more complicated than a tokens-per-second headline. At 2,400 output tokens, the model returned no artifact. At larger budgets, it solved the cases. Across five text-only paperwork cases, MTP was stricter than non-MTP, but only slightly cheaper and slightly faster.
So this is no longer just a runtime note. It is a reminder that local benchmark rows need closure cost: strict pass, core pass, elapsed time, completion tokens, reasoning tokens, and visible artifact size. MTP helped here, but the bigger story is still budget-to-artifact.