Claims meet paperwork.
Practical local LLM articles, model reports, and benchmark notes. Each piece separates specs, runtime claims, observed outputs, and actual case results.
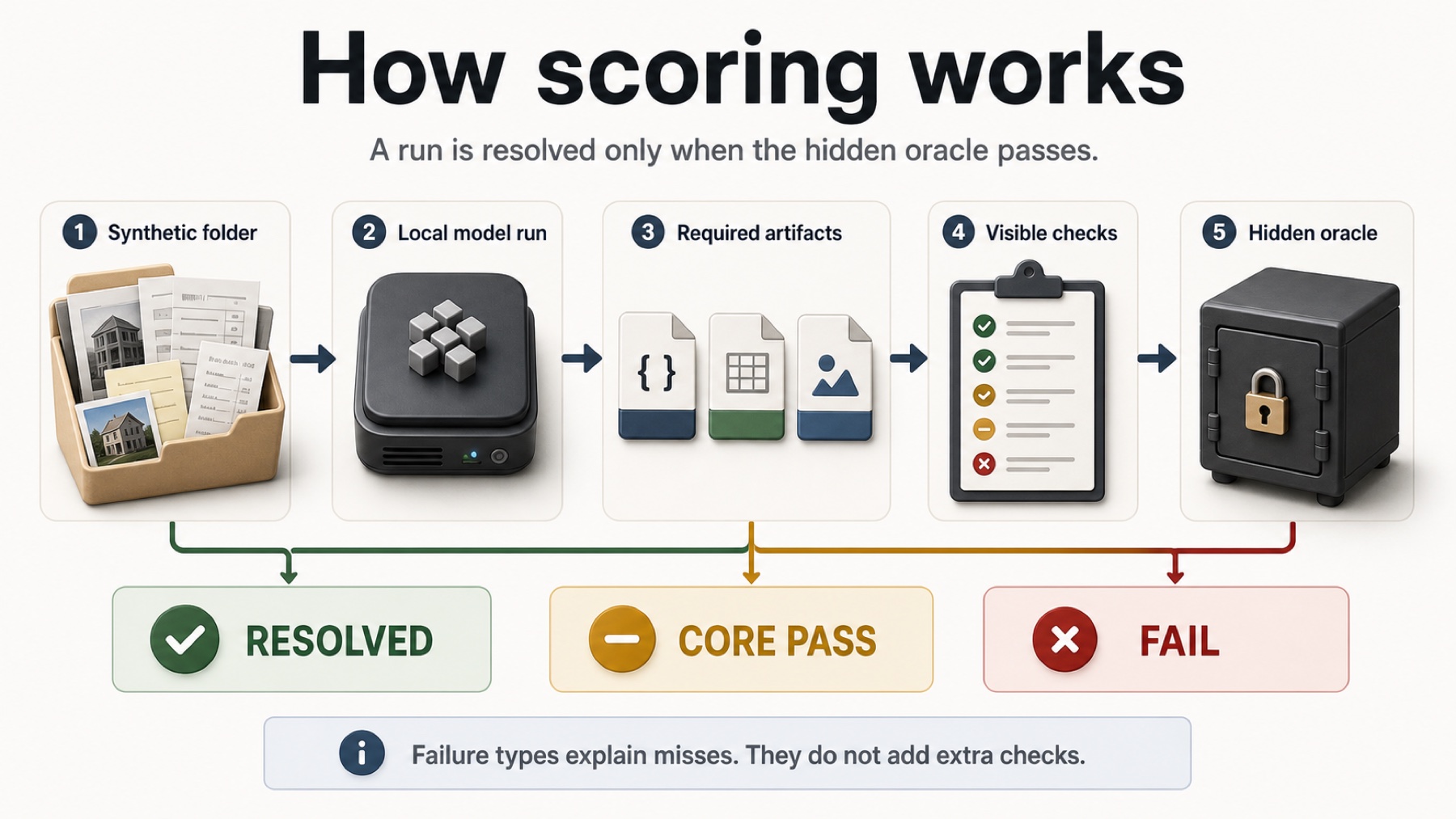
How to read these
These are not universal model reviews. They compare public positioning and specs against one concrete workflow suite, then link the raw run outputs.
Local runs and reference/API runs are marked separately, with run outputs linked for inspection.
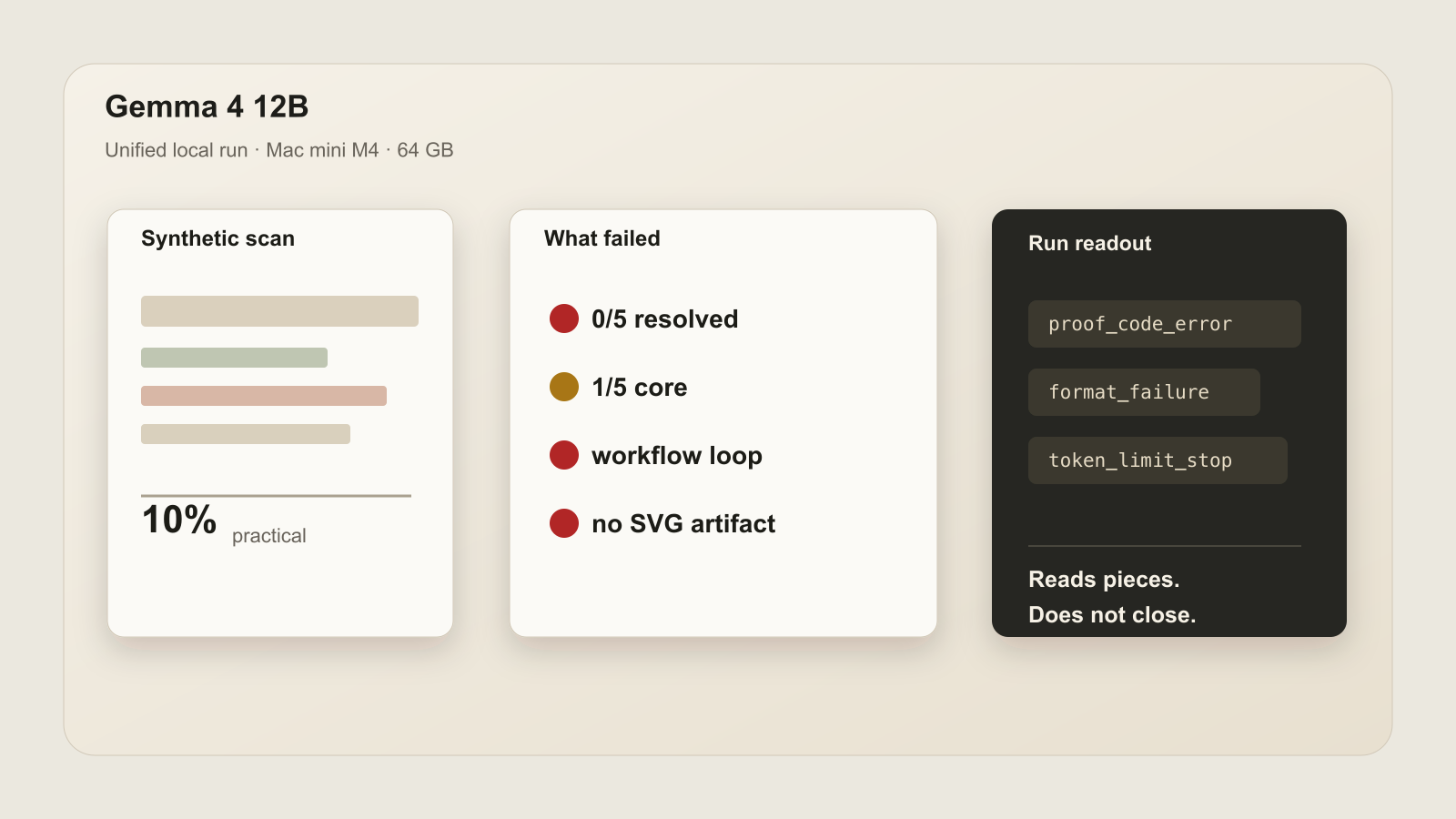
Gemma 4 12B Unified read pieces, but did not close the work
Gemma 4 12B Unified was added as a local LM Studio run on the Mac mini M4. It found parts of the paperwork, but the final result was harsh: 10% Practical Score, 0/5 resolved generated-image cases, workflow loops, and no parseable City Plan SVG.
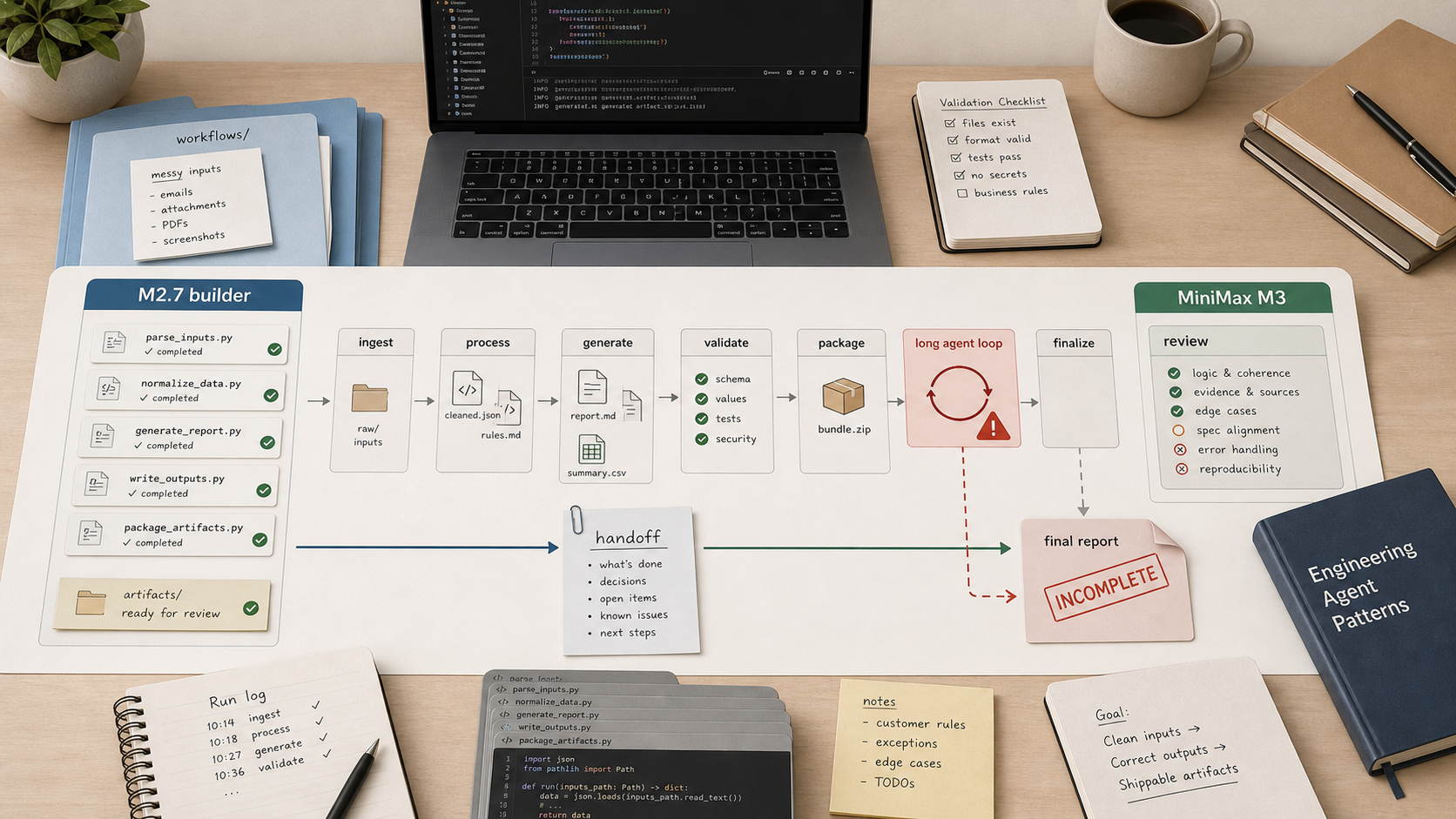
MiniMax M3 looks broken in long agent loops
MiniMax M3 can score well in bounded benchmark work and still break in long autonomous agent loops. This field note is about that second failure mode: many files, generated assets, validation, and a final report that never cleanly arrives.

MiniMax M3 Free leads the paperwork benchmark, with one ugly SVG caveat
MiniMax M3 Free is the top Practical Score on Local Model Bench: 8/9 resolved and 88.9% across the current paperwork suite. That does not make it a universal agent winner. It is a provider-routed benchmark result, and it still produced no parseable City Plan SVG after a 600 second timeout.
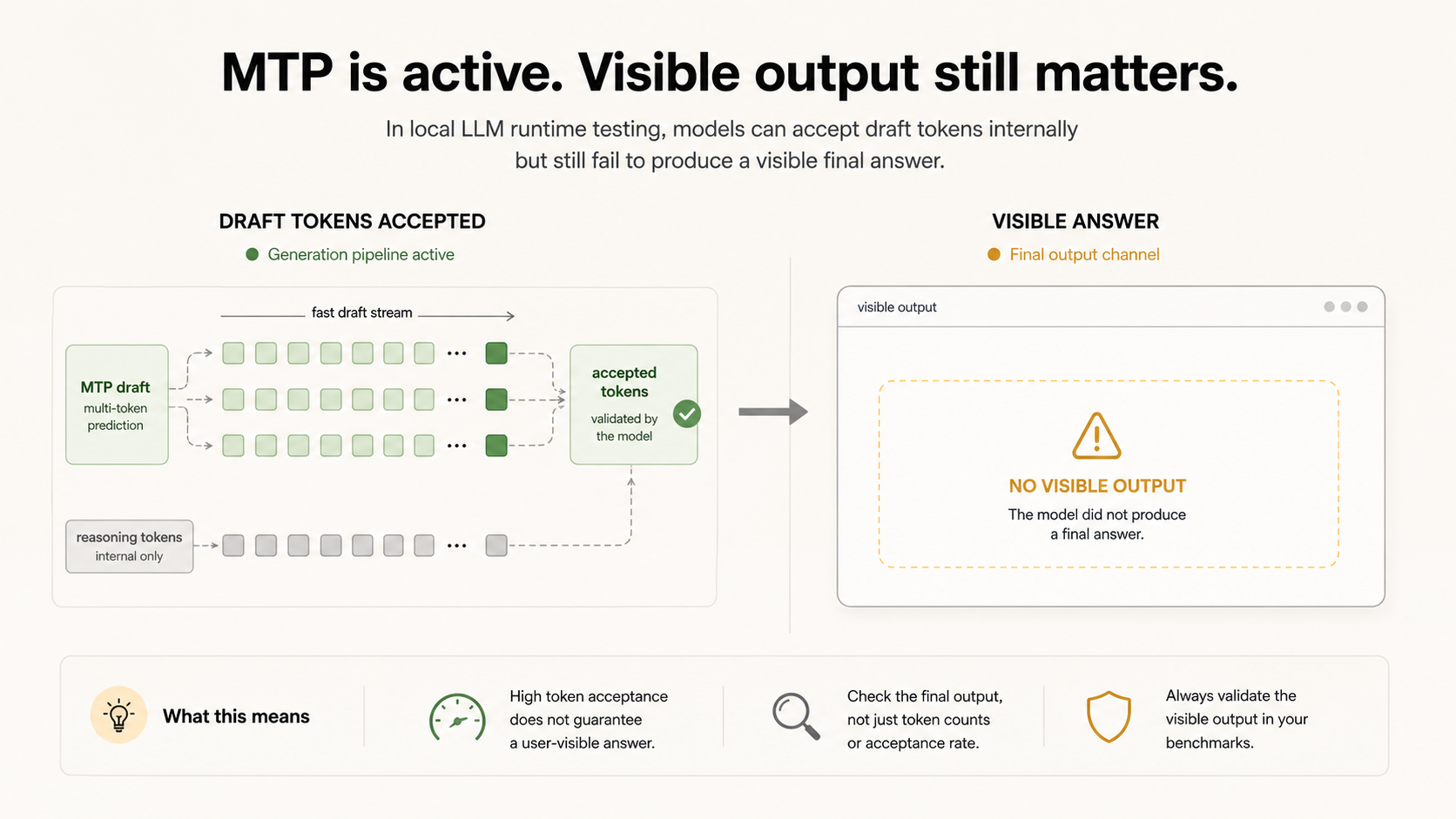
Qwen3.6 MTP worked. The artifact still matters.
Qwen3.6 MTP is the local model people are arguing about right now. In our Mac mini checks, LM Studio showed a small speed gain and llama.cpp showed a tiny gain with the right flags. In a five-case text-only paperwork run, MTP solved 5/5 strict while non-MTP solved 4/5 strict. The speed difference was tiny.
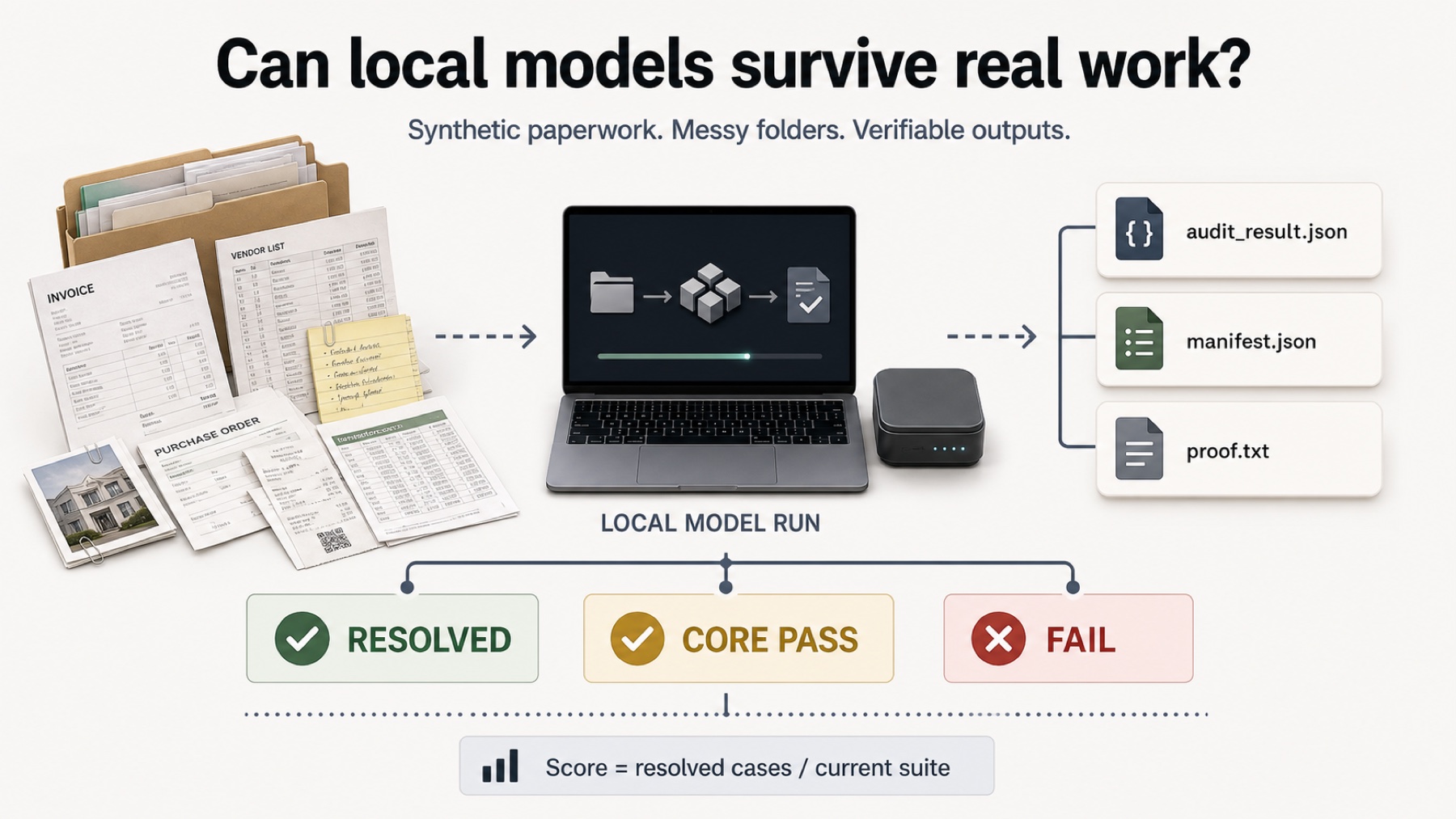
Best local LLMs for private document work
The useful question is not which local LLM sounds smartest in chat. It is which one can survive private desktop work: scans, CSVs, messy folders, revised invoices, evidence paths, proof codes, and exact final files.

New model candidates, same paperwork problem
Three newer candidates were added to Local Model Bench. The useful signal was not that every model failed. It was where they failed: proof codes, evidence paths, workflow closure, and provider constraints that should not be confused with model capability.

Benchmark-smart is not the same as work-ready
Public benchmarks are useful. They are also clean. Real work is full of stale files, wrong attachments, hidden assumptions, and final artifacts that actually have to exist. A model can be good at the leaderboard shape and still be bad at finishing the job.
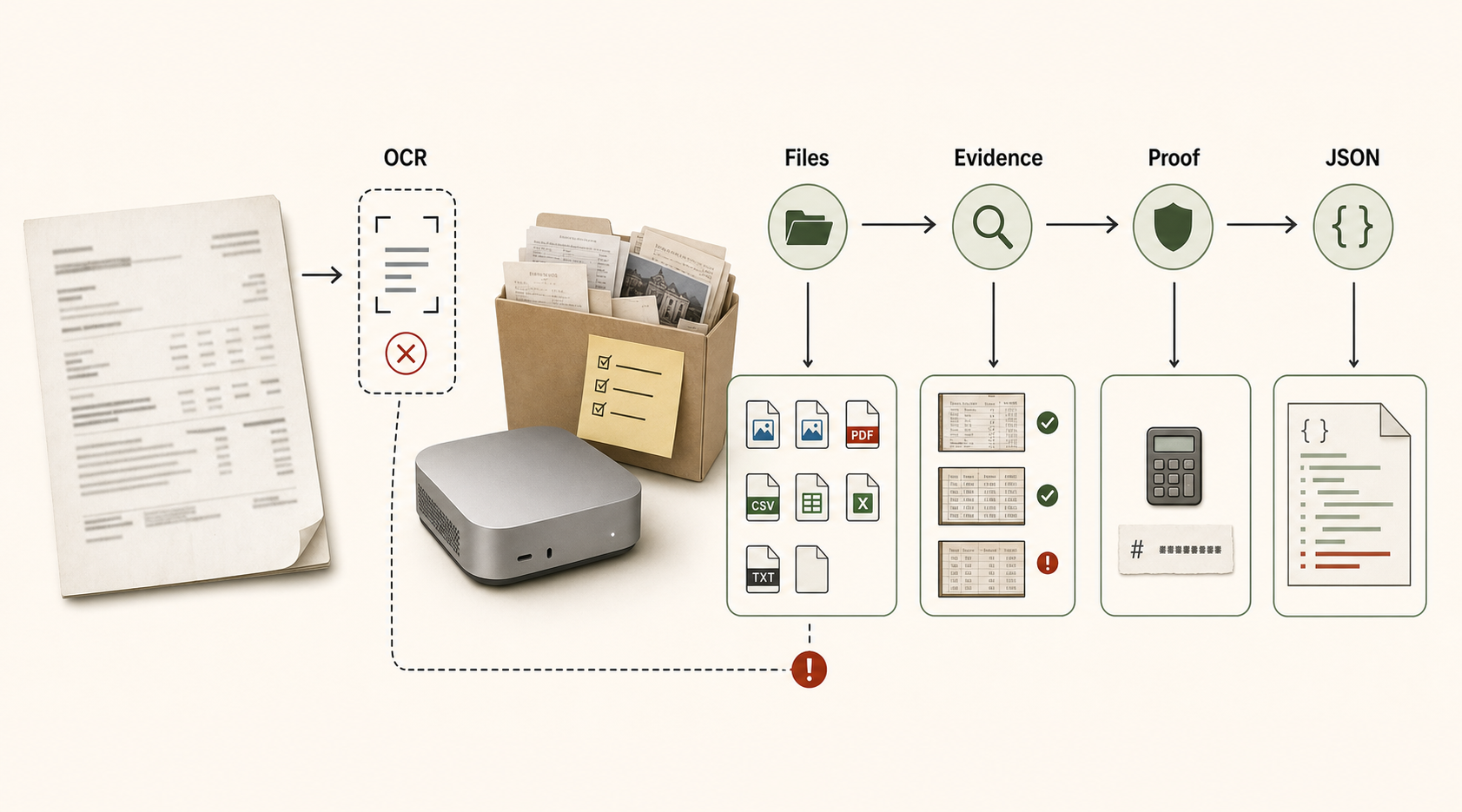
OCR is the wrong word for this benchmark
Local Model Bench uses generated invoice images, but it is not mainly an OCR test. The hard part starts after the page has been read: selecting the right files, rejecting stale documents, reconciling CSV rows, citing evidence, writing artifacts, and passing a hidden oracle.
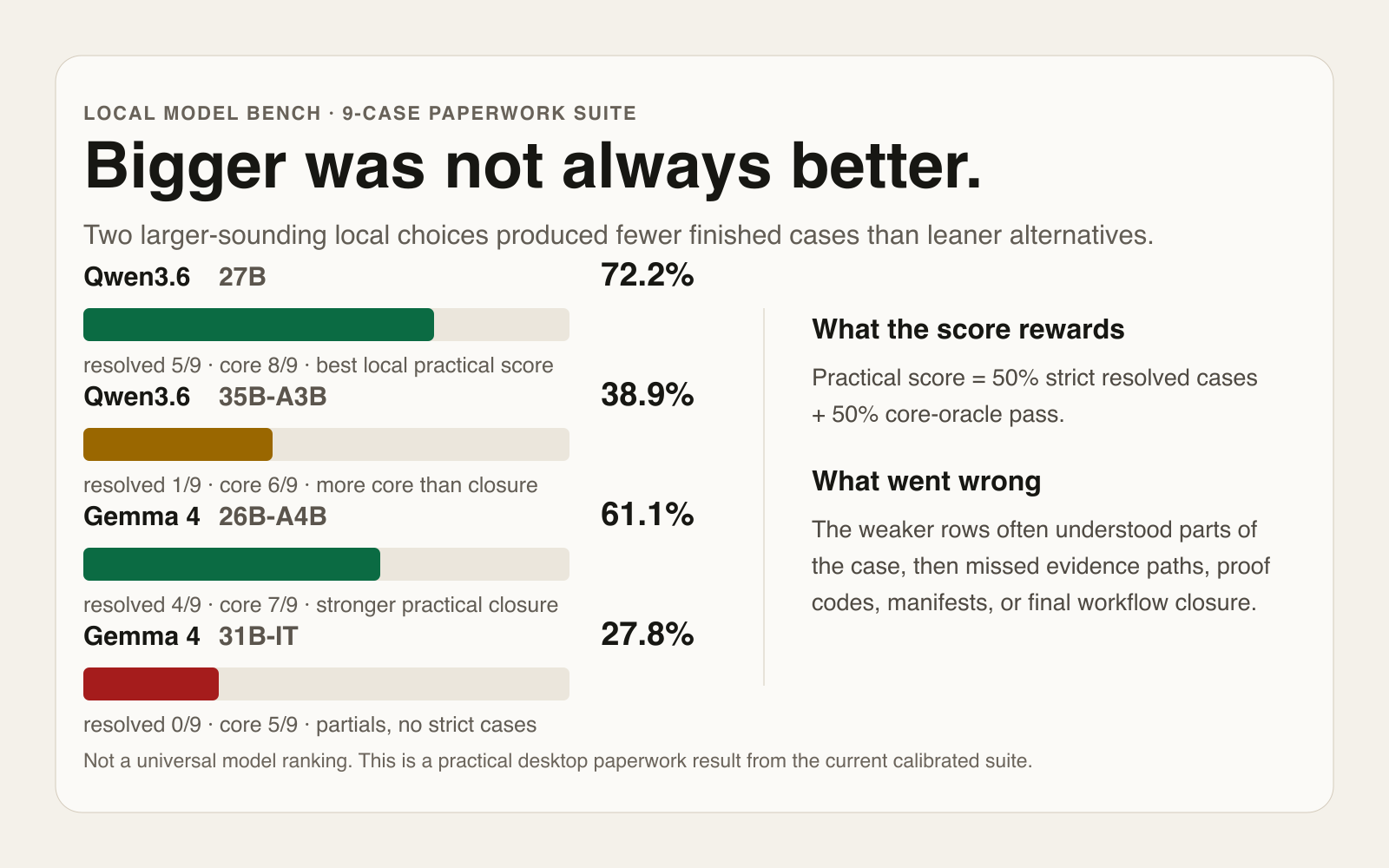
Bigger was not always better in the paperwork benchmark
In the current nine-case paperwork suite, two larger-sounding local model choices produced fewer finished cases than leaner alternatives. That does not prove small models are better. It shows that parameter count and model labels are poor substitutes for checking whether the final work actually got done.
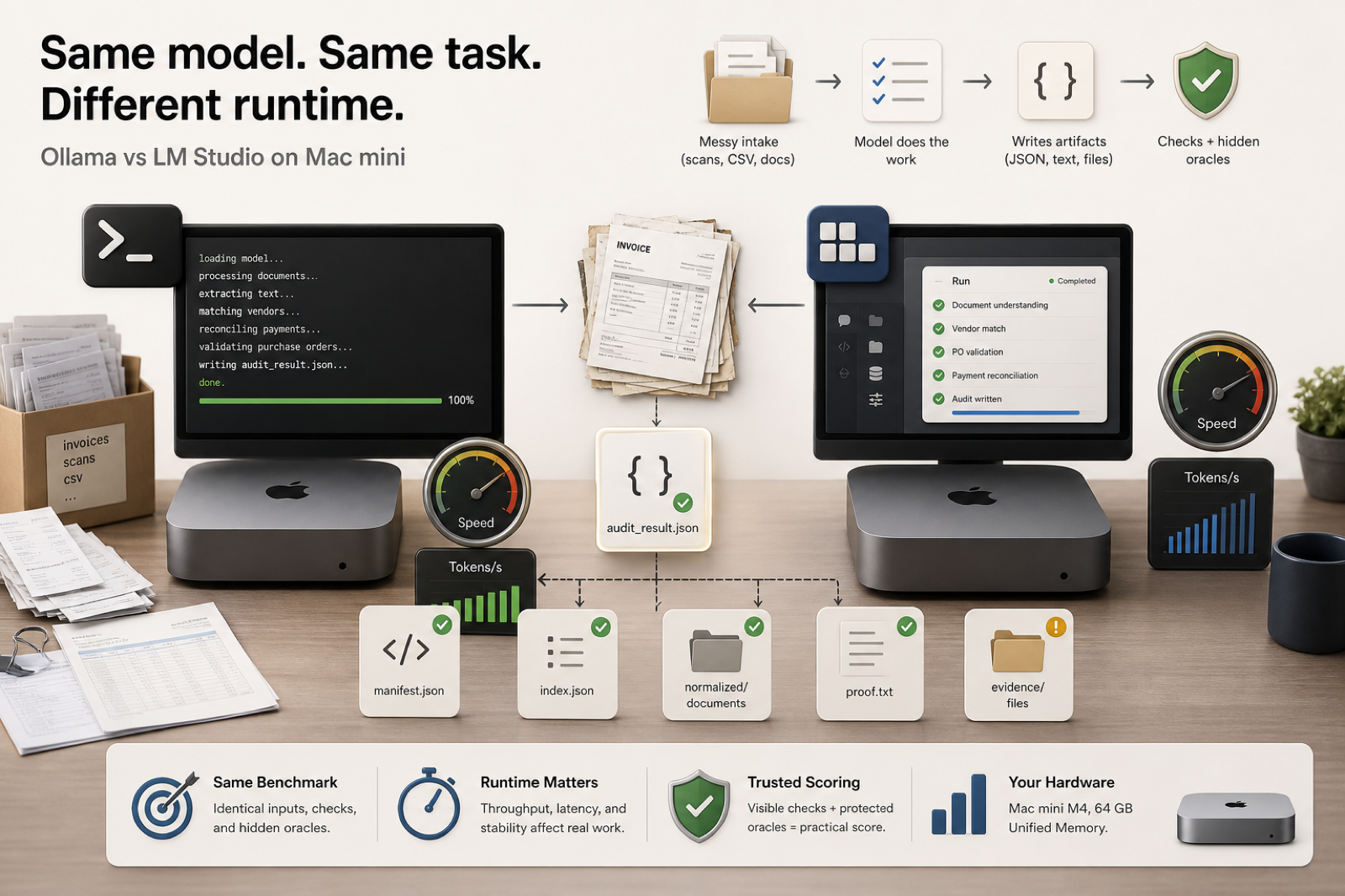
Ollama vs. LM Studio: speed is not the whole benchmark
We ran the same Mistral Small family through LM Studio and Ollama on a Mac mini M4. Ollama was slightly faster in the tiny runtime check, but both runtimes exposed the same practical problem: the model still failed exact paperwork closure.
Gemini 3.5 Flash can draw SVG. The runner was the problem.
A first Gemini 3.5 Flash SVG run looked like a model failure. It was not. The OpenAI-compatible API path let hidden thinking consume the output budget, so the model returned planning fragments instead of a complete SVG. The native Gemini API with thinkingBudget: 0 produced a valid City Plan SVG and passed 3/3 checks. A later native text-only paperwork run landed at 2/5 strict cases, 3/5 core passes, and 15/20 checks.
Qwen3.6 27B on a Mac mini: the current local model to beat
Qwen3.6 27B is the strongest local LM Studio result in the current Local Model Bench suite. It did not solve everything, but it handled synthetic paperwork better than the larger-looking local alternatives we tested so far.

How to benchmark local LLMs for private documents
A useful local LLM benchmark should test more than chat quality. For private document work, the hard part is messy inputs, source selection, structured artifacts, hidden oracles, and exact workflow closure.
Chrome Gemini Nano: the browser is a local runtime now
Chrome's built-in Prompt API exposed `LanguageModel` on this Mac and downloaded Gemini Nano into a browser profile. It can run Local Model Bench's text-only paperwork cases locally in Chrome, but the first pass shows the same old problem: plausible answers are easier than exact closure.
Paperwork Text-Only: separating logic from vision
The text-only paperwork benchmark gives models normalized document extracts instead of generated scans. It is not the main leaderboard, but it answers a useful question: can the model close the bookkeeping logic once OCR and vision are removed from the problem?
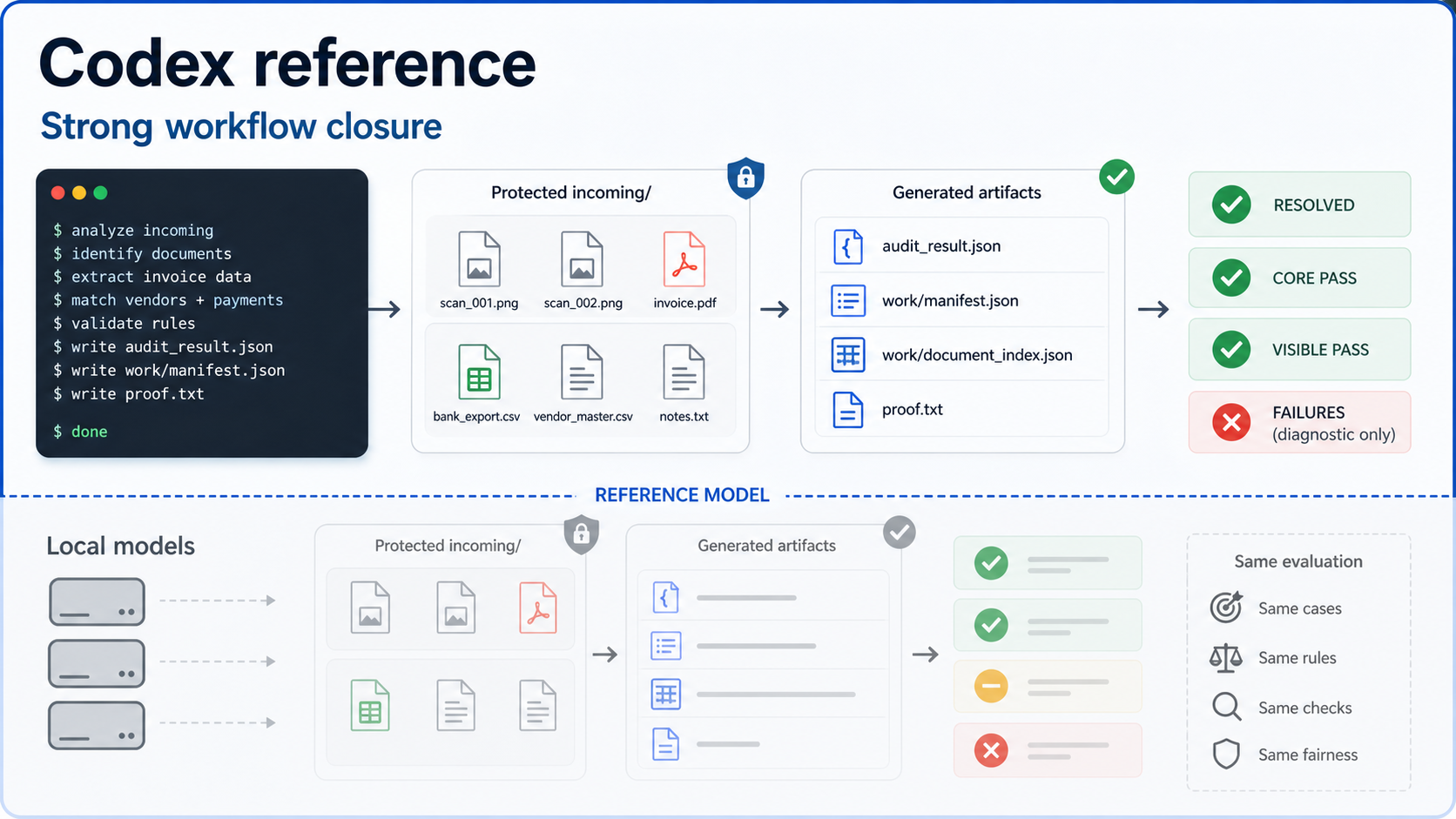
Why Codex can lose to a local model
In the text-only paperwork benchmark, a local Qwen model beats the Codex reference row. That does not mean the local model is generally smarter. It means this benchmark rewards exact workflow closure, and Codex repeatedly missed the boring final checksum.
Why “looks right” is not enough
A model can read the invoice, name the right vendor, and still fail the job. Local Model Bench separates rough understanding from clean workflow closure because real paperwork work ends with correct files, evidence, and proof.

Gemini 2.5 Flash: good at reading, sloppy at closure
Gemini 2.5 Flash understood many of the synthetic paperwork cases, but repeatedly failed the exact final contract: valid JSON, proof codes, and workflow checksum closure.

Gemini 3.1 Flash Lite: cheap, quick, still not closed
Gemini 3.1 Flash Lite ran the full current suite quickly and cheaply. It reached five core passes, generated a valid City Plan SVG, and still resolved none of the nine practical paperwork cases strictly.

LFM2 24B A2B: fast smoke test, zero workflow wins
LFM2 24B A2B passed a trivial JSON smoke test, then failed every current Local Model Bench paperwork case. The issue was not speed. It was task completion: wrong audit logic in scan cases, and no valid artifacts in agentic workflow cases.
Granite Vision 4.1 4B read the scans, then failed the job
Granite Vision 4.1 4B handled individual synthetic invoice scans better than expected, but did not complete the paperwork audit. The available local multi-image path failed, and the pipeline workaround still broke at final JSON and proof-code closure.

Qwen3 VL 32B in a paperwork workflow test
Qwen3-VL is positioned as a strong vision-language model for long-context image reasoning. In this benchmark it read many document facts correctly, then repeatedly lost the run at proof codes, duplicate-risk logic, and workflow closure.

Gemma 4 26B A4B: useful local MoE, not the final answer
Gemma 4 26B A4B is listed as an on-device MoE model with 26B total and roughly 4B active parameters. In Local Model Bench it remains a useful local baseline, but newer Qwen3.6 27B results moved the local bar higher.

Gemma 4 31B: dense model, brittle closure
Gemma 4 31B is positioned as the dense, all-parameters-active sibling of the Gemma 4 family. It often understood the broad document situation, but the strict benchmark contract punished it hard.
OpenAI GPT-5.5 (Codex CLI): what clean workflow closure looks like
Codex is not a local LM Studio run. It is kept as a reference line for what stronger agentic tooling does on the same public cases, using the same artifacts and hidden-oracle checks.