OpenAI GPT-5.5 (Codex CLI): what clean workflow closure looks like
Codex is not a local LM Studio run. It is kept as a reference line for what stronger agentic tooling does on the same public cases, using the same artifacts and hidden-oracle checks.
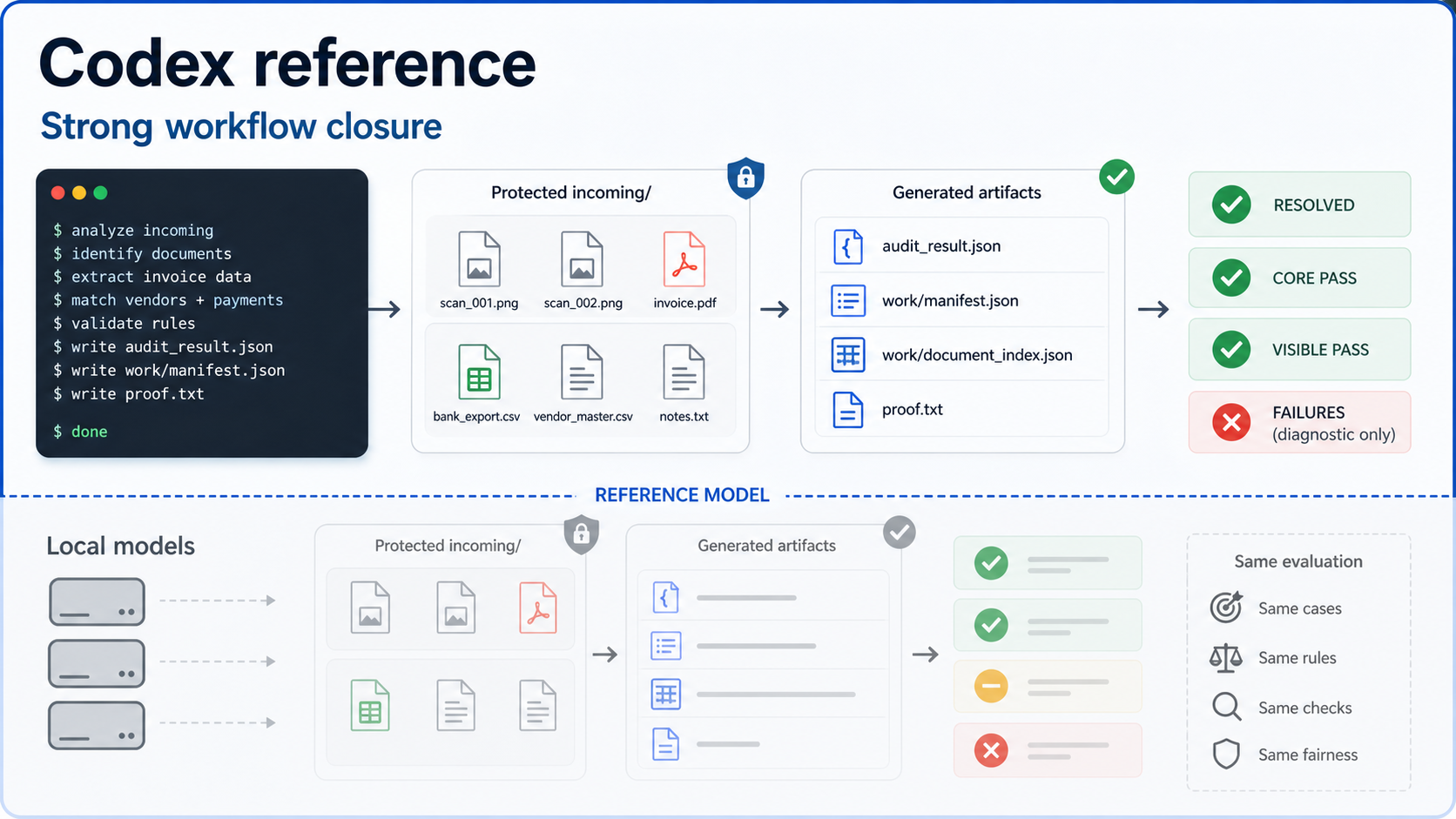
The Codex row is intentionally not presented as a local-model victory lap. It is a ceiling/reference line: a stronger agentic coding environment running the same public paperwork cases.
That reference is useful because it shows which failures are benchmark difficulty rather than local-only weakness. Even the reference run still missed proof/evidence details, which is exactly why Local Model Bench separates core pass from resolved pass.
Model Context
- Model family
- OpenAI GPT-5.5 via Codex CLI
- Run type
- Reference/API tooling run
- Local hardware
- Not a local LM Studio run
- Benchmark role
- Workflow closure ceiling
- Comparison note
- Shown separately from local rows
Positioned As
- The reference row is included for practical calibration, not model marketing.
- It asks a simple question: what does a stronger agentic tool do when the task requires reading files, preserving sources, writing artifacts, and passing hidden oracles?
What We Actually Tested
- The same generated invoice and workflow cases were used.
- The run was scored with the same resolved/core split and the same hidden-oracle checks.
- Because it is not a local LM Studio run, it should not be read as a local deployment recommendation.
What Worked
- Best current practical score across the full public case set.
- Strong at preserving protected input folders while producing required artifacts.
- Most failures were narrow near misses rather than broad document misunderstanding.
Where It Broke
- Still failed one case strictly and had proof/evidence misses.
- Not directly comparable to local-only LM Studio runs.
- Useful as a ceiling/reference, not as the point of the site.
Readout
The reference run shows why the benchmark is not just OCR. Clean workflow closure means final files, protected inputs, proof codes, and evidence all line up. That is the behavior local models are being measured against.