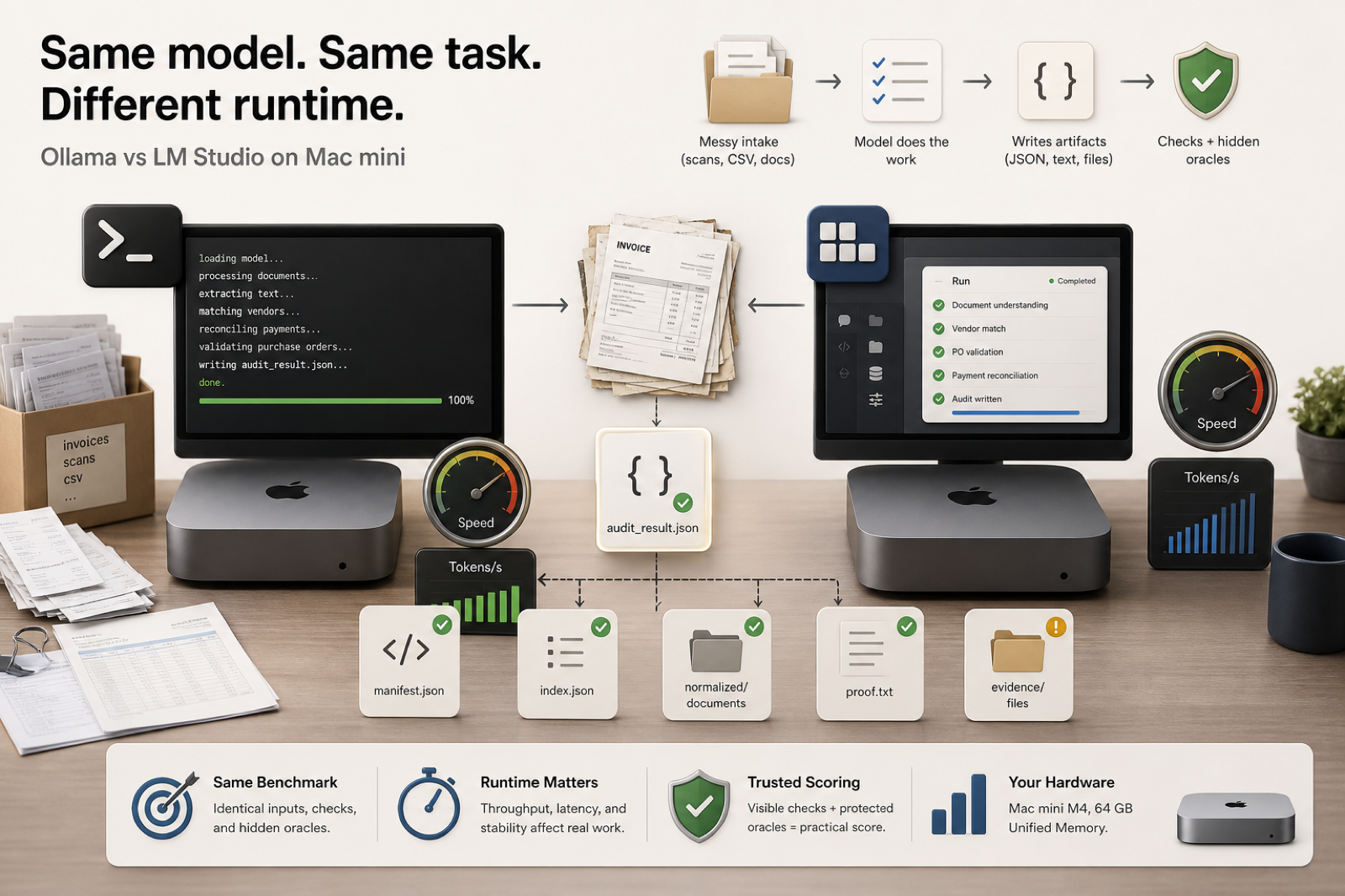
What was tested
The first pass used three tiny reproducible prompts: one JSON invoice extraction, one proof-code calculation, and one short CSV artifact. The goal was not to rank the model broadly. The goal was to see whether the same model family behaves differently through two local runtimes.
After that, the Ollama run was pushed through the Paperwork Text-Only diagnostic: five synthetic invoice cases where the model receives normalized document extracts instead of generated invoice images. That removes OCR and vision from the equation and tests bookkeeping, classification, warning logic, evidence paths, and exact final JSON.
- Hardware: Mac mini M4, 64 GB unified memory
- LM Studio model: mistralai/mistral-small-3.2
- Ollama model: mistral-small:24b
- Mini runtime prompts: JSON, proof-code calculation, CSV
- Follow-up diagnostic: Paperwork Text-Only, five cases
Runtime readout
In the tiny runtime check, Ollama was slightly faster by native generation speed: about 14.7 tokens per second compared with about 12.7 tokens per second for LM Studio. Wall-clock time was less clean because the first request includes runtime overhead and model loading behavior.
That makes the result useful but limited. A small prompt set is good for smoke testing and catching obvious runtime differences. It is not enough to declare one runtime better for real work.
- LM Studio mini-run: 6/6 prompts completed, about 12.7 tok/s average
- Ollama mini-run: 6/6 prompts completed, about 14.7 tok/s average
- Ollama exposed native timing fields; LM Studio exposed OpenAI-compatible usage fields
- Both runtimes produced visible output for all mini prompts
Where the simple speed story breaks
The proof-code prompt is where the neat runtime story fell apart. The expected operation required extracting the numeric part of an invoice ID and adding it to two other terms. LM Studio left the invoice ID inside the expression. Ollama returned a short numeric answer, but it was also wrong.
That matters because the Paperwork Trial is full of these small closure steps. A model can read most fields correctly and still lose the case because it cannot finish the arithmetic, evidence, warning, or proof-code step exactly.
Paperwork Text-Only result
On the five-case Paperwork Text-Only diagnostic, Ollama's `mistral-small:24b` reached the same practical result as the earlier LM Studio run: 0/5 strict resolved cases and 1/5 core passes. Ollama did a little better on check count, mostly because it produced valid JSON more consistently.
That distinction is worth keeping. Format robustness is real. But it is not the same as resolving the workflow. The model still missed proof codes, warning codes, invoice classification details, duplicate-risk handling, or exact totals across the harder cases.
- Ollama `mistral-small:24b`: 10/20 checks, 0/5 strict, 1/5 core
- LM Studio `mistral-small-3.2`: 8/20 checks, 0/5 strict, 1/5 core
- Practical score for both: 10%
- Ollama looked slightly cleaner on JSON/format handling
- Neither runtime made the model reliable on exact paperwork closure
What this says about runtimes
This is not a claim that Ollama is better than LM Studio, or that LM Studio is better than Ollama. It is a narrower observation: for this model family and this small local setup, Ollama was a little faster and slightly cleaner on formatting, but the model's core weakness remained.
That is the practical lesson. Runtime matters for user experience, battery, memory, batch throughput, and whether a model is pleasant to run. But Local Model Bench is not trying to reward pleasant failure. The final artifact has to be correct.
Practical readout
For Mistral Small on this benchmark, changing the local runtime did not turn a weak paperwork result into a strong one. It changed the shape of the failure slightly.
That is still useful. If a model produces malformed output in one runtime and valid JSON in another, the runtime deserves credit. But if both runs miss the same proof and bookkeeping logic, the bottleneck is probably the model-task fit, not just the wrapper around it.