Short answer
As of the current public Local Model Bench suite, the best local row for private document work is Qwen3.6 27B. It is not a magic model and it does not close every case, but it has the best practical balance we have seen locally across generated invoice scans and messy workflow folders.
Gemma 4 26B-A4B remains the useful local baseline. It is fast enough to work with, often understands the broad situation, and is a better everyday comparison point than many smaller models. But it is no longer the local row to beat.
The dense Gemma 4 31B result is the useful warning. Bigger and denser did not automatically mean better in this workflow. It often looked close, then lost the run on exact closure.
- First local model to try here: Qwen3.6 27B
- Useful local baseline: Gemma 4 26B-A4B
- Do not judge by chat feel alone
- Do not judge by parameter count alone
- Check the final files
The benchmark angle
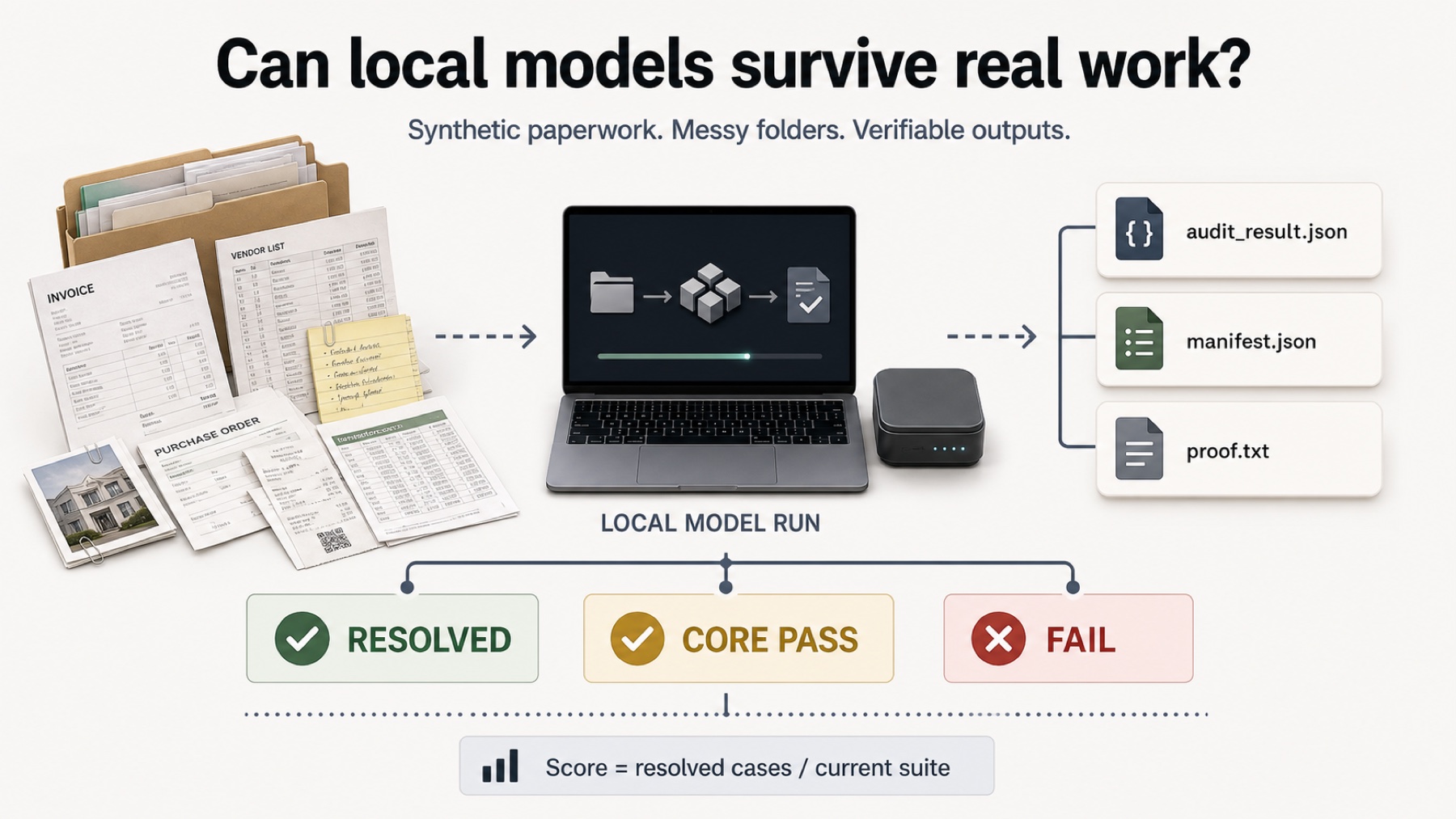
Local Model Bench is built around a narrow practical question: can local models handle private desktop work? The current suite uses synthetic invoice cases, messy intake folders, generated scans, CSV exports, hidden oracles, and visible run outputs. It is not a universal intelligence ranking.
The benchmark deliberately favors boring work. That is the point. A useful desktop assistant has to finish exact tasks, not just produce plausible commentary. It has to read sources, choose active files, ignore stale drafts, produce structured artifacts, cite evidence paths, and close the final proof step.
A model that looks polished can still lose because the file is in the wrong directory or the proof code is wrong.
Current practical readout
The strongest local row in the current public suite is Qwen3.6 27B. It is not perfect, but it handled the combined paperwork and workflow cases better than the other local models tested so far.
Gemma 4 26B-A4B remains useful, especially as a practical local MoE candidate. I would keep it in the comparison set when testing any new local candidate.
Smaller models can still be interesting. Some are fast, cheap to run, and decent at text-only diagnostic tasks. But in the main multimodal paperwork suite, the hard failures are usually not style problems. They are workflow failures: wrong document selection, missing evidence, proof-code errors, duplicate-risk misses, or incomplete artifacts.
- Best current local practical result: Qwen3.6 27B
- Useful local MoE baseline: Gemma 4 26B-A4B
- Good diagnostic split: Paperwork Text-Only
- Still hard for most models: agentic folder workflows
- Separate sanity check: City Plan SVG
Vision is only one part
Document work is often described as a vision problem, but that is only partly true. A model must read the scan, yes. It also has to reconcile the scan against bank rows, vendor status, purchase orders, previous invoices, notes from accounts payable, and revision hints in messy folders.
That is why the site keeps text-only diagnostics separate. If a model improves sharply when normalized text extracts replace images, the bottleneck may be OCR or layout understanding. If it still fails text-only, the issue is deeper: bookkeeping logic, schema discipline, or final workflow closure.
A text-only model can still be useful if another tool extracts the document text first. It just should not be mixed into the same score as a model that handled the original scans.
What I would actually run
For private document work on a Mac mini-class machine, I would start with three lanes rather than one winner.
First, run the strongest local multimodal/document candidate you can fit comfortably. In our current table that means Qwen3.6 27B. Second, keep Gemma 4 26B-A4B as a practical baseline because it is useful and not wildly expensive to run. Third, keep a text-only lane for non-vision models so you can tell whether a failure is image reading or workflow logic.
That setup is less glamorous than a single winner. It is also more honest. The question is not which model wins a chart. The question is which setup gets your documents into a correct final artifact with the least human cleanup.
- Multimodal lane: generated scans and messy folder cases
- Text-only lane: normalized extracts and same oracle logic
- Runtime lane: speed, timeout, visible output, token budget
- Visual sanity lane: constrained SVG or diagram output
- Manual review lane: inspect raw outputs before trusting automation
How to read the scores
The main practical score combines two signals. Resolved means the whole case passed, including hidden oracle, proof code, final artifacts, and protected-file rules. Core pass means the central audit facts were right even if exact closure failed. That split matters because a proof-code miss should not look identical to a wrong invoice decision.
The site also shows failure types. They are diagnostics, not extra score penalties. A `proof_code_error`, `duplicate_risk_missed`, or `missing_or_wrong_evidence` label tells you why a model lost the case. It does not secretly add more failed checks.
What not to over-read
This is a small benchmark. It should not be read as a universal claim about model intelligence, all document tasks, or every possible runtime setting.
It is also not financial, tax, or legal advice. The cases are synthetic bookkeeping tasks designed to test extraction, reconciliation, artifact discipline, and hidden-oracle closure.
The useful claim is narrower: if a local model cannot close these small synthetic workflows, you should be careful before trusting it with messier real private folders.
What should be tested next
The next useful expansion is not a bigger generic prompt set. It is more private-work tasks: contracts with conflicting amendments, insurance forms, synthetic appointment packets, messy support exports, local repo repair, and inbox attachment cleanup. Each task needs visible artifacts and hidden oracles.
The benchmark should also become easier to reproduce. A public runner and documented case format would make the site less like a blog and more like infrastructure.
Bottom line
For private document work, the best local LLM is not necessarily the model with the biggest context window or the prettiest chat answer. It is the model that can finish boring local work without leaking files, hallucinating fields, or producing an artifact that fails the next step.
That is the current bar: not magic, not AGI, not another leaderboard badge. Just local models doing private desktop work well enough that a human can verify instead of repair.