The problem with plausible answers
A model answer can look good while still being unusable. It can name the right vendor, repeat the right invoice total, and write a confident summary. Then it can put the wrong warning code in JSON, use a filename where the case asks for a document ID, forget an intermediate artifact, or calculate a proof code from the wrong numbers.
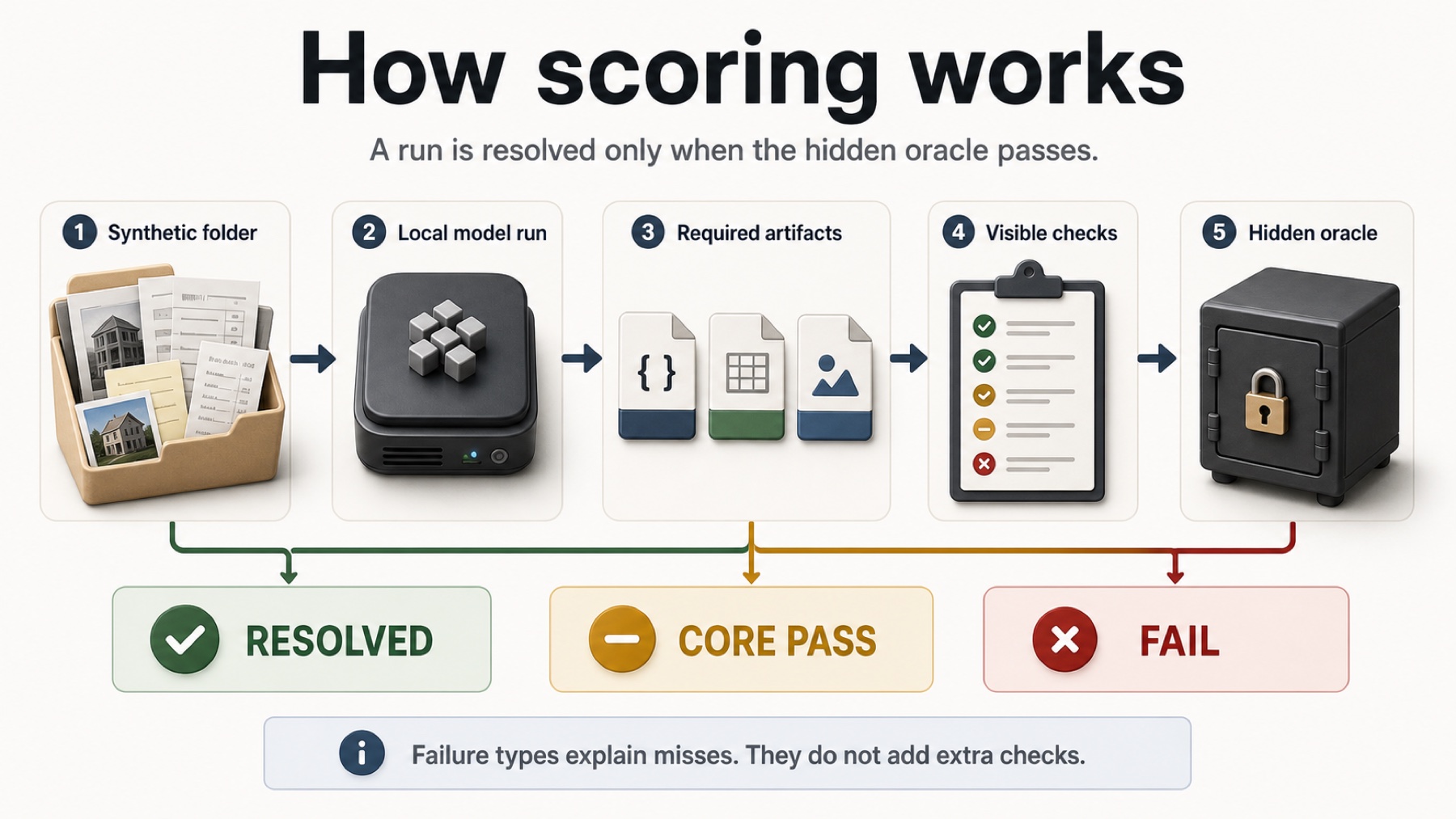
That kind of failure is easy to miss in a chat transcript. It is harder to miss when the task has a final artifact and an oracle. Local Model Bench is built around that difference.
What resolved means
A resolved case means the model finished the whole job. It did not merely understand the broad situation. It returned the required files, kept protected source folders unchanged, matched the hidden oracle, used acceptable evidence, and closed the final proof-code check.
This makes the score harsher than a human vibe check. That is intentional. A local model used for private paperwork is not just writing an opinion. It is supposed to produce something a user or script can rely on.
Why core pass exists
The benchmark also tracks core pass because not all failures are equally bad. If a model identifies the right invoice, vendor, payment status, and review decision but misses the proof code, that is different from selecting the wrong document entirely.
Core pass is the near-miss signal. It tells us when the model understood the central audit facts but failed exact closure. That distinction matters for model selection. A model with many core passes may be useful with human review. A model with neither resolved nor core passes is just not doing the work.
The checksum idea
The proof code is deliberately boring. It is a small checksum-style field derived from visible final values in the case. It is not a secret trick and it is not meant to be clever. It checks whether the model can keep its own output internally consistent.
This is where many strong-looking answers fail. The model can describe the case correctly, then put the wrong final integer in `proof_code` or leave it as an arithmetic expression. That is a real failure if the task demands a usable JSON artifact.
Why hidden oracles matter
Visible checks are useful but insufficient. They can confirm that a file exists, JSON parses, or required keys are present. They cannot tell whether the model chose the revised invoice instead of the withdrawn one, ignored the correct distractor, or mapped a payment reference to the right final document.
Hidden oracles let the public case remain inspectable while preventing a model from passing through superficial formatting alone. They also make failure analysis more honest: the site can show whether a failure was format, evidence, protected-file, classification, warning, or proof related.
What this says about local models
The current results suggest a practical pattern. Many local models can produce something that looks useful. Fewer can resolve the full case. The difference is not academic. It is the difference between a tool that helps a person review paperwork and a tool that can safely complete a workflow.
That is why Local Model Bench should stay focused on finished artifacts. The world already has enough benchmarks where models answer clean prompts. The more interesting local question is whether they can survive messy, private, ordinary work.