Why this model is interesting
Qwen3.6 27B sits in the awkwardly useful middle. It is much larger than the tiny local models that are easy to run but often brittle, yet still small enough to be realistic on a serious desktop machine. LM Studio exposes it as a local model, and the public Qwen model page positions Qwen3.6 27B as a dense open-weight model rather than a remote-only API product.
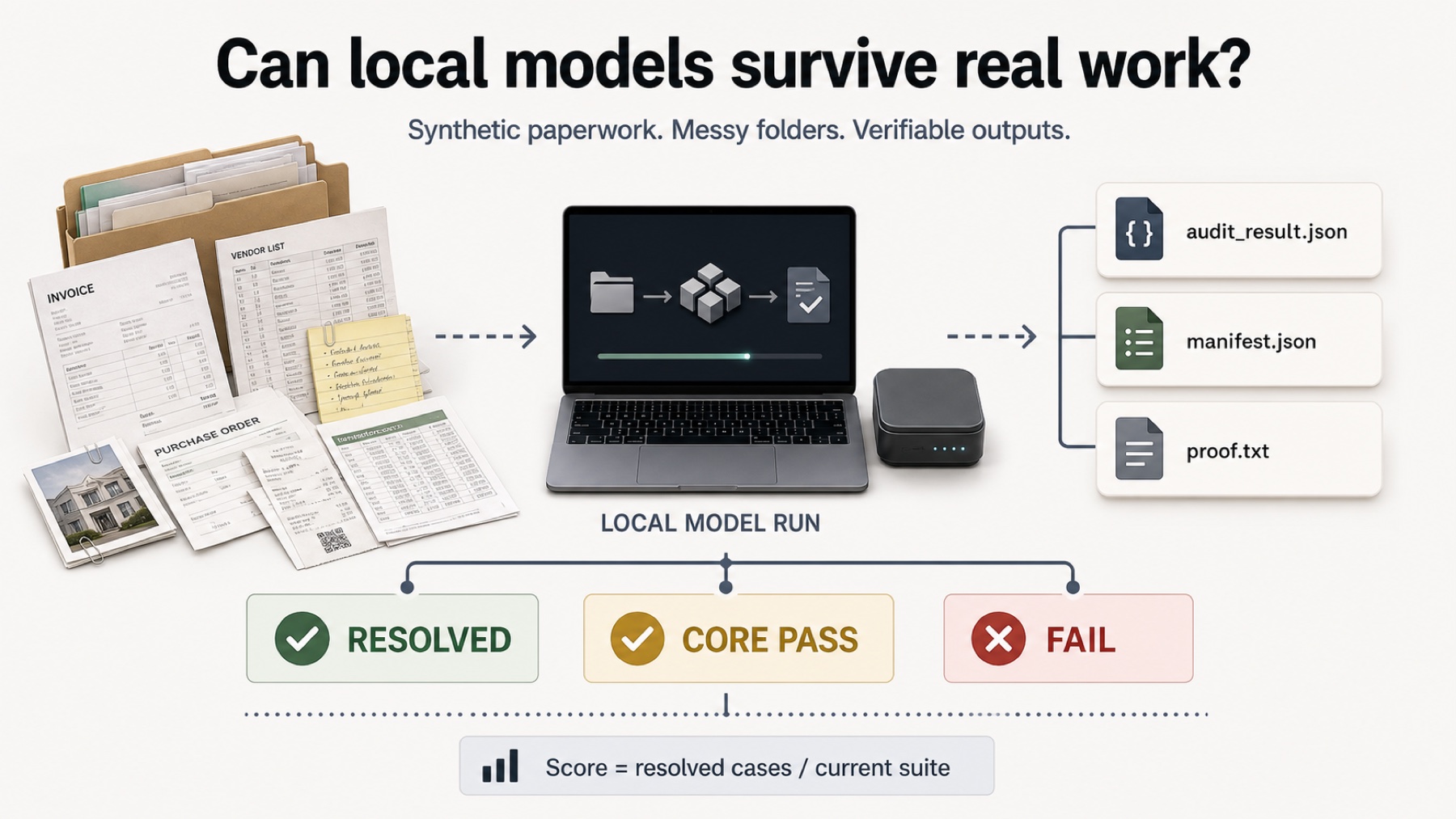
That makes it a good Local Model Bench candidate. The question is not whether it can win a polished public benchmark. The question is whether it can read and close boring private work without sending the documents to a cloud model.
The practical score
Across the current scored paperwork suite, Qwen3.6 27B reached a 72.2% Practical Score. That number comes from the site's 50/50 split: half strict resolved cases, half core-oracle passes. In plain language, the model solved five of nine cases strictly and reached core-pass level on eight of nine.
That is the best local result currently shown on the site. It is also meaningfully below the reference ceiling. The model is useful, but not autonomous. The most honest read is: strong local assistant, not fire-and-forget paperwork agent.
- Paperwork image suite: 3/5 strict resolved, 17/20 checks
- Workflow cases: 2/4 strict resolved, two additional near misses
- Overall scored suite: 5/9 strict resolved
- Core pass signal: 8/9
- Text-only diagnostic: 4/5 strict resolved
What it got right
The strongest signal is not one lucky case. Qwen3.6 27B did well across both parts of the practical suite. It handled several generated-invoice cases and also completed two of the agentic workflow folders, where the model has to select active source files, avoid distractors, preserve protected input folders, and write final artifacts.
It also did well in text-only mode. That matters because it suggests the model's failures are not simply about bookkeeping logic. When the document text is normalized, it can close most of the cases. The remaining problem is the combined real-world stack: image reading, source selection, file handling, and exact final closure.
Where it still failed
The misses are the part worth studying. Qwen3.6 27B still had proof-code errors, evidence-path format misses, and at least one duplicate-risk miss. Those are not dramatic failures. They are boring failures. That is exactly why they matter.
A model that gets the main story right but misses the checksum or evidence path is useful with review, but risky without review. Local Model Bench is intentionally harsh about this because the output is supposed to be a final artifact, not a helpful paragraph.
Compared with other local rows
The result also explains why the leaderboard can surprise people. Bigger or more exotic local models did not automatically win. Some models produced plausible output but failed exact closure. Others did better in text-only mode than in image mode. Qwen3.6 27B is currently strong because it balanced document understanding, structured output, and workflow completion better than the rest of the local group.
That does not mean it will stay on top. The benchmark is small, and new local models arrive constantly. But it gives us a concrete baseline: any new local candidate should beat Qwen3.6 27B on the same nine scored cases, not just sound impressive in a chat demo.
Should you try it?
If your local machine can run it comfortably, yes. It is the first model in our current set that feels like a serious candidate for private document triage. The right use case is not unsupervised accounting. The right use case is assisted review: extract likely facts, flag mismatches, produce a draft JSON result, then keep a human in the loop.
For Local Model Bench, Qwen3.6 27B is now the local baseline to beat. A new model has to do more than produce clean prose. It has to resolve cases.