Why this does not contradict the leaderboard
Local Model Bench has a separate MiniMax M3 Free run log where the provider-routed model leads the current Practical Score. That result is real and should stay visible.
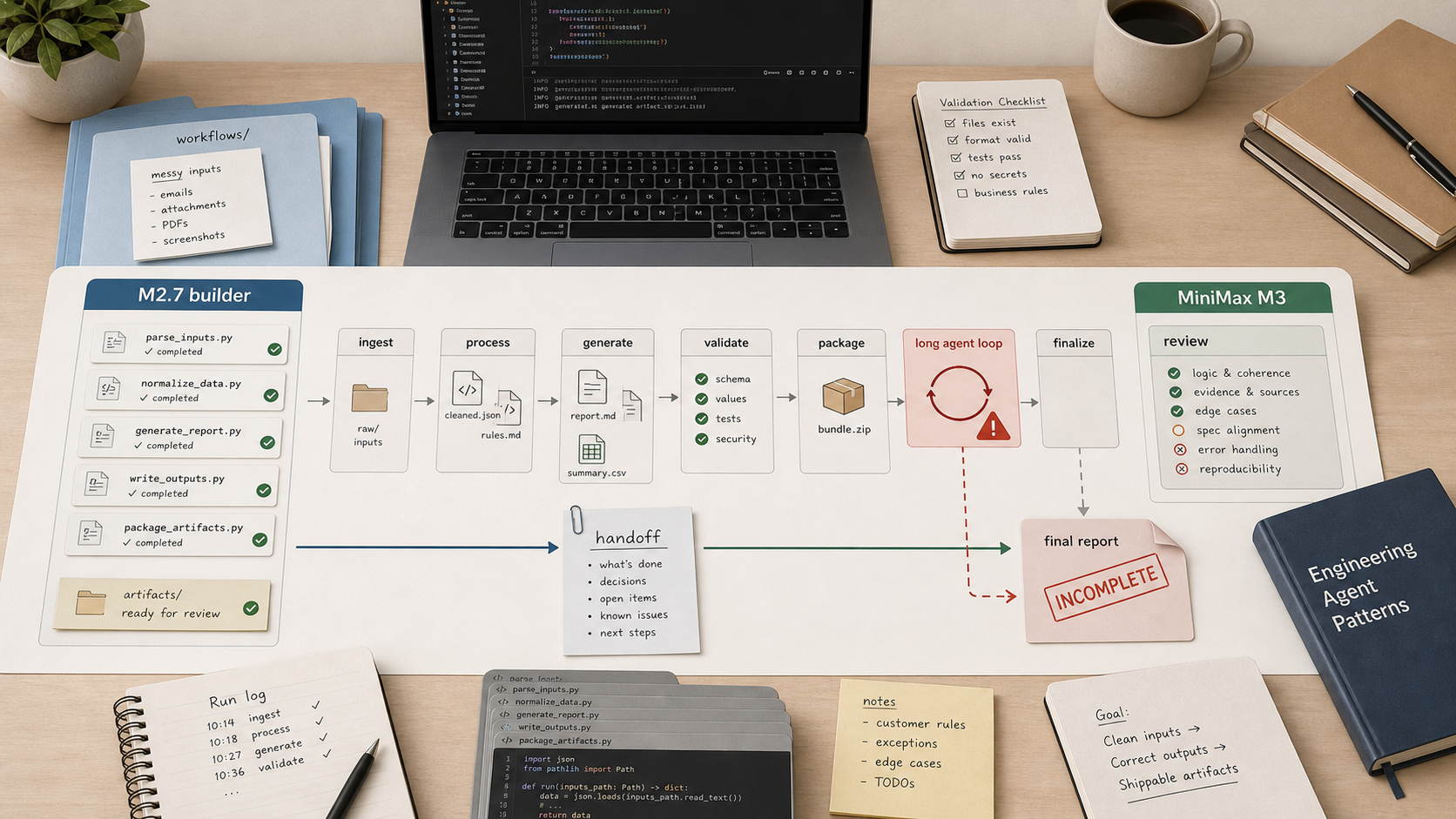
This note is about a different work shape: long autonomous OpenCode/MiniMax-Code-style sessions with many generated files, images, validators, and a final report. In that shape, the model repeatedly did most of the work and then failed to close.
So the useful readout is not "M3 is good" or "M3 is bad". It is narrower: M3 can be strong in bounded paperwork benchmark cases, while still being unsafe as a long-running autonomous builder.
What worked
M3 completed short server/SRE-style diagnosis tasks.
It handled a large-context multi-turn probe up to roughly 135k input tokens.
In an article-quality probe, M3 produced the cleaner reporter-style article compared with M2.7-highspeed. M2.7 was faster, but invented unnamed quotes, which is a serious problem for journalism-style work.
Where it broke
The breakage showed up in long autonomous local work.
In heavy site/content generation, M3 scaffolded or produced partial artifacts and then stalled before the dataset, final assets, validator, or report existed.
In a 30-article workflow, M2.7-highspeed completed all 30 articles plus validator/report in about 671 seconds. M3 timed out at 900 seconds with 23 markdown files and no validator/report.
In a five-article fair test, M3 passed without images in about 332 seconds. Add locally generated SVG images and it timed out at 600 seconds: five articles and four of five SVGs existed, but no validator/report/contact sheet.
The diagnosis
This does not look like a basic intelligence failure. It looks like a tool-loop, reasoning-loop, or finish-condition failure.
M3 often completes most of the real work, then fails to terminate cleanly or fails to produce the final validator/report.
Images and assets make the problem worse, but they are not the only cause. The common trigger is long serial work with many local file operations and a finalization step.
The practical workaround
Use M2.7-highspeed as the builder: bulk writing, repetitive edits, many files, boilerplate, and mechanical implementation.
Use M3 as the planner, reviewer, editor, and final consistency pass.
Do not hand M3 a huge all-in-one prompt with images, many generated files, validation, and a final report. That is exactly where the current behavior becomes unfit for productive use.