What ran
The model was run locally through LM Studio as `google/gemma-4-12b` on a Mac mini M4 with 64 GB unified memory.
It ran the five generated-image Paperwork Trial cases, the four agentic Paperwork Workflow cases, and the City Plan SVG sanity check.
The generated-image cases use synthetic invoice scans plus bank exports, vendor records, purchase orders, and exact `audit_result.json` checks. The workflow cases add messy folders, protected source files, intermediate artifacts, and proof files.
The headline result
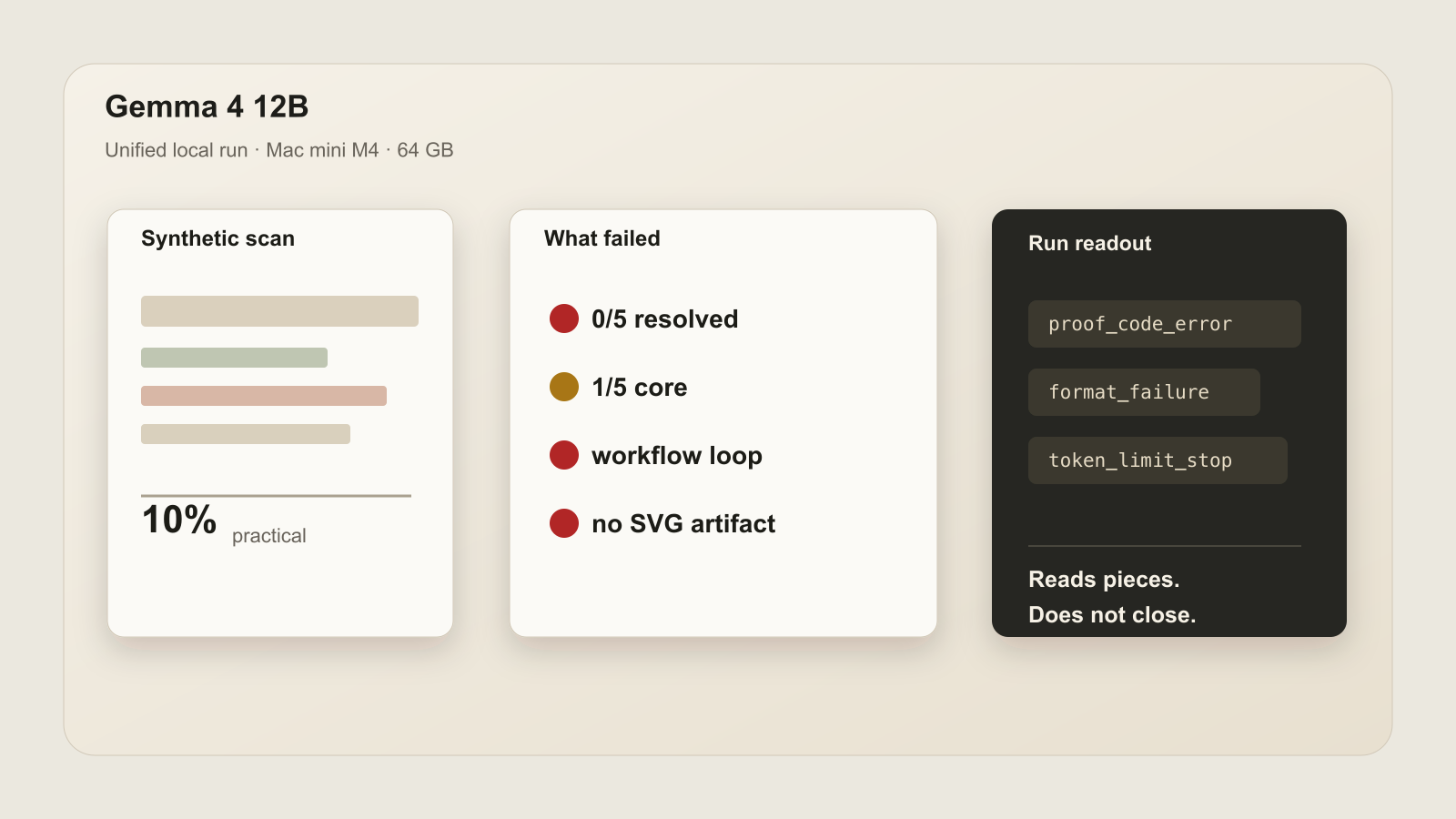
On the generated-image Paperwork Trial, Gemma 4 12B Unified scored 10% Practical Score: zero of five cases resolved, one of five core passes, four of five visible passes, and zero hidden passes.
That split matters. The visible checks show the model was often in the neighborhood. The hidden oracle shows it did not close the job.
The recurring failures were not exotic: wrong or missing evidence, ignored-document ID errors, invoice classification mistakes, total calculation errors, warning-code problems, and proof-code failures.
The workflow run exposed the harder failure
The agentic workflow cases were worse.
In Workflow Case 04, the model produced some artifacts, but the final output was malformed and the run hit a token-limit/repair-loop pattern. The scored trace records `lmstudio_action_loop -> token_limit_stop`.
Cases 05, 06, and 07 failed around required artifacts and final output discipline. That is the practical problem: a local assistant that cannot reliably stop, write the required files, and leave a verifiable result is not doing the office work yet.
SVG did not rescue it
The City Plan SVG run also failed.
Gemma 4 12B Unified got one of three automated checks, but returned no parseable standalone SVG artifact. The run page therefore has no visual preview.
That is a clean failure. It is not a weak drawing. It is an absent artifact.
Practical readout
This is not a claim that Gemma 4 12B Unified is useless.
It is a claim about this workload. In the current Local Model Bench shape, the model can read pieces of the folder but fails the closure layer: exact JSON, evidence, hidden oracle, proof code, workflow artifacts, and constrained SVG output.
For private desktop work, that distinction is the point. A model that sounds close but leaves broken artifacts still leaves the human doing the cleanup.