Granite Vision 4.1 4B read the scans, then failed the job
Granite Vision 4.1 4B handled individual synthetic invoice scans better than expected, but did not complete the paperwork audit. The available local multi-image path failed, and the pipeline workaround still broke at final JSON and proof-code closure.
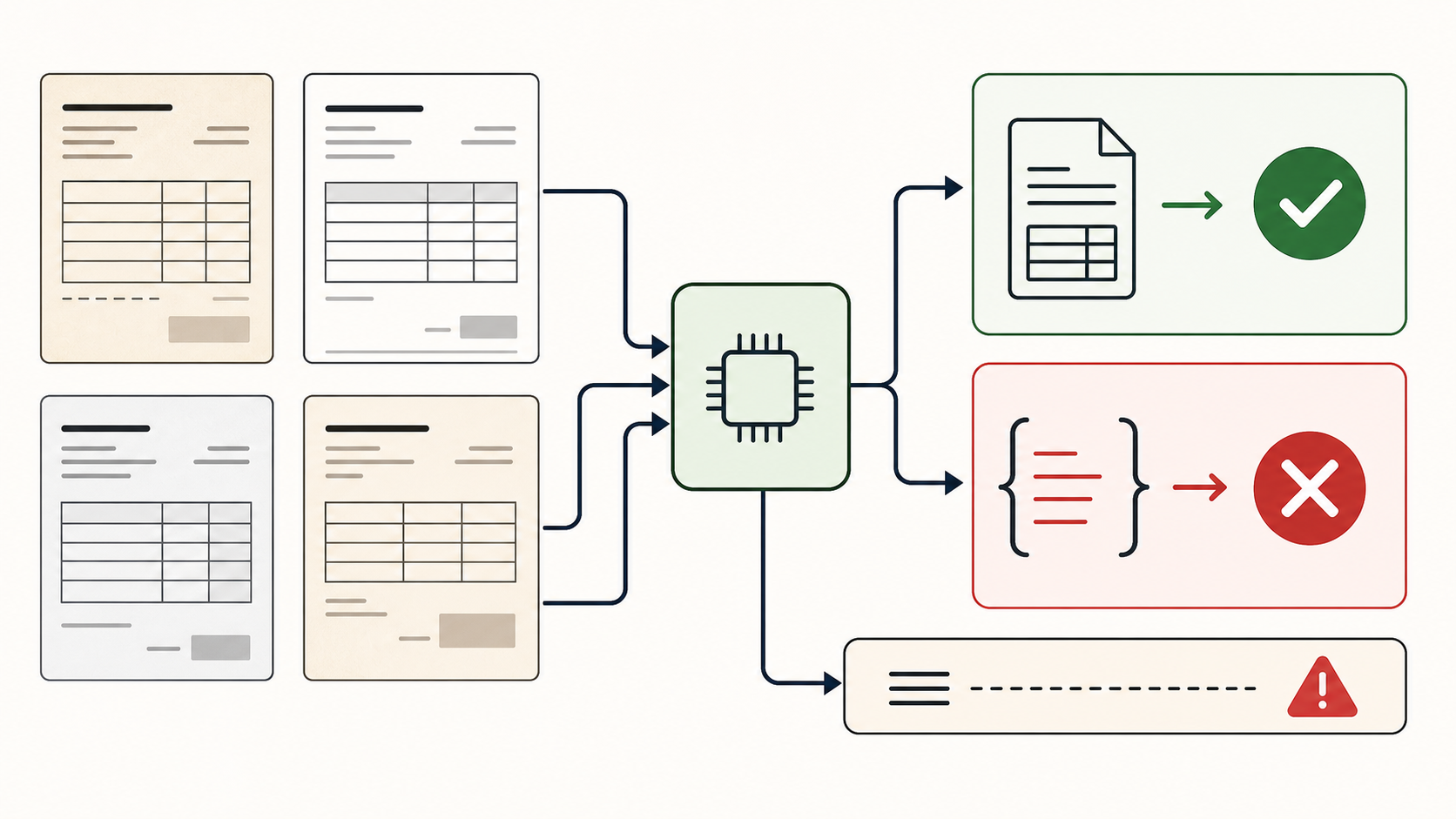
Granite Vision 4.1 4B is positioned as a small open vision-language model for enterprise document extraction. That is close enough to Local Model Bench territory to be interesting: invoice scans, structured fields, source evidence, and final audit artifacts.
The result was split. The model extracted visible facts from individual scans well. But the benchmark is not an OCR demo. The task ends only when the model produces a valid final audit JSON with correct evidence and a computed proof code. Granite did not get there.
Model Context
- Model family
- IBM Granite Vision
- Run type
- Local MLX-VLM run
- Local hardware
- Mac mini M4, 64 GB unified memory
- Model size
- 4B vision-language model
- Benchmark role
- Document-vision candidate
Positioned As
- The Hugging Face listing presents Granite Vision 4.1 4B as an image-text model in IBM's Granite family.
- Hugging Face Transformers documentation includes Granite4Vision support and example usage for `ibm-granite/granite-vision-4.1-4b`.
- The practical promise is not just seeing an image. For document work, the useful version is field extraction plus reliable structured completion.
What We Actually Tested
- The direct local multi-image run failed in the available MLX-VLM setup with a tensor shape error before producing a benchmark answer.
- A second local pipeline tested the model one image at a time, then asked it to finish the same audit from those extracted scan notes plus CSV files.
- The pipeline run read the documents well enough to identify the real invoices, the non-invoice quote, the short-paid note, and the under-review stamp.
- The final output still failed the benchmark: `proof_code` was emitted as an arithmetic expression instead of a JSON integer, and the proof used the wrong source numbers.
What Worked
- Extracted visible fields from individual invoice scans surprisingly well.
- Correctly recognized the quote as not an invoice.
- Found important visual annotations including short payment and under-review status.
Where It Broke
- The direct multi-image local run did not complete in the available runtime.
- The completed pipeline workaround produced invalid JSON.
- The proof code was left as a formula and calculated from the wrong values.
- That makes it unsuitable as an end-to-end paperwork agent in this setup.
Readout
Granite Vision 4.1 4B looked like a useful extractor, not a complete paperwork worker. For Local Model Bench, reading the scans is only the first half of the job. The model still has to close the workflow, and this run did not.