The surprising comparison
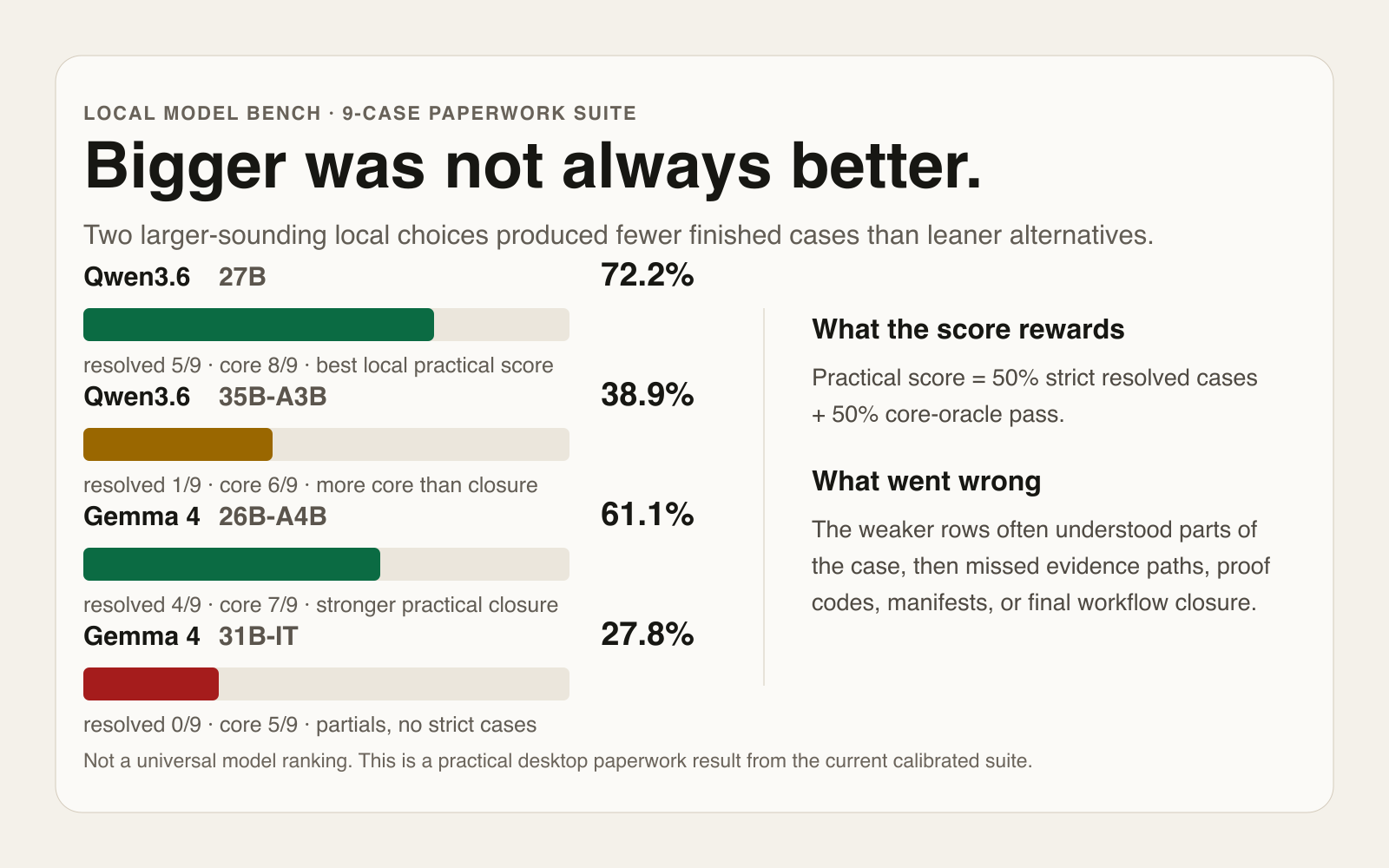
The current local result to beat is qwen3.6-27b. It scored 72.2%, with 5/9 resolved cases and 8/9 core passes.
The larger-sounding qwen3.6-35b-a3b did not beat it. It scored 38.9%, with 1/9 resolved cases and 6/9 core passes.
That is the interesting part. The 35B-A3B run was not simply useless. It had six core passes. But it finished only one case strictly. In this benchmark, that gap between mostly understanding the case and actually completing it is the whole point.
The Gemma comparison showed the same pattern. gemma-4-26b-a4b scored 61.1%, with 4/9 resolved cases and 7/9 core passes. gemma-4-31b-it scored 27.8%, with 0/9 resolved cases and 5/9 core passes.
Where the bigger rows lost points
The weaker runs tended to fail in unglamorous places.
For qwen3.6-35b-a3b, the recurring problems were evidence path formatting, manifest errors, missing or wrong evidence, and one case where the final audit result landed in the wrong location.
For gemma-4-31b-it, the recurring problems included proof-code errors, duplicate-risk misses, invoice classification mistakes, total calculation errors, and normalized text issues in workflow cases.
Those are not abstract intelligence failures. They are desktop-work failures. A local document model has to do more than read the page. It has to choose the right source files, ignore stale or irrelevant documents, preserve protected folders, write the expected artifacts, keep evidence paths consistent, and finish the final proof step.
This is not a small-model victory lap
This result should not be overread. The benchmark does not prove that smaller models are generally better. It does not prove that Qwen 27B is always better than Qwen 35B-A3B, or that Gemma 26B-A4B is always better than Gemma 31B-IT.
Different prompts, runtimes, quantizations, context settings, or task types could change the ranking. A larger model may still be better at long-form writing, code reasoning, broad knowledge, or other benchmark categories.
There is also a useful control: in the Paperwork Text-Only diagnostic, qwen3.6-27b and qwen3.6-35b-a3b both reached 80.0%. That suggests the full paperwork suite is not just testing language reasoning. It is also testing OCR and vision behavior, file selection, workflow discipline, and exact final artifact handling.
The practical readout
For local private-document work, do not buy the model label. Test the workflow.
The model that looks stronger on paper may still be worse at finishing a messy folder task. The model that produces a convincing explanation may still miss the proof code. The model that gets the invoice total right may still write the result into the wrong place.
Local Model Bench is trying to measure that boring last mile. The question is not which model sounds biggest. The question is which model can survive the actual folder.
Right now, on this nine-case paperwork suite, bigger was not always better.