The OCR demo ends too early
An OCR demo usually stops at extraction. It asks whether the system can read the invoice number, capture the total, preserve the table, or return text in the right order.
That is useful. It is also not enough for private document work.
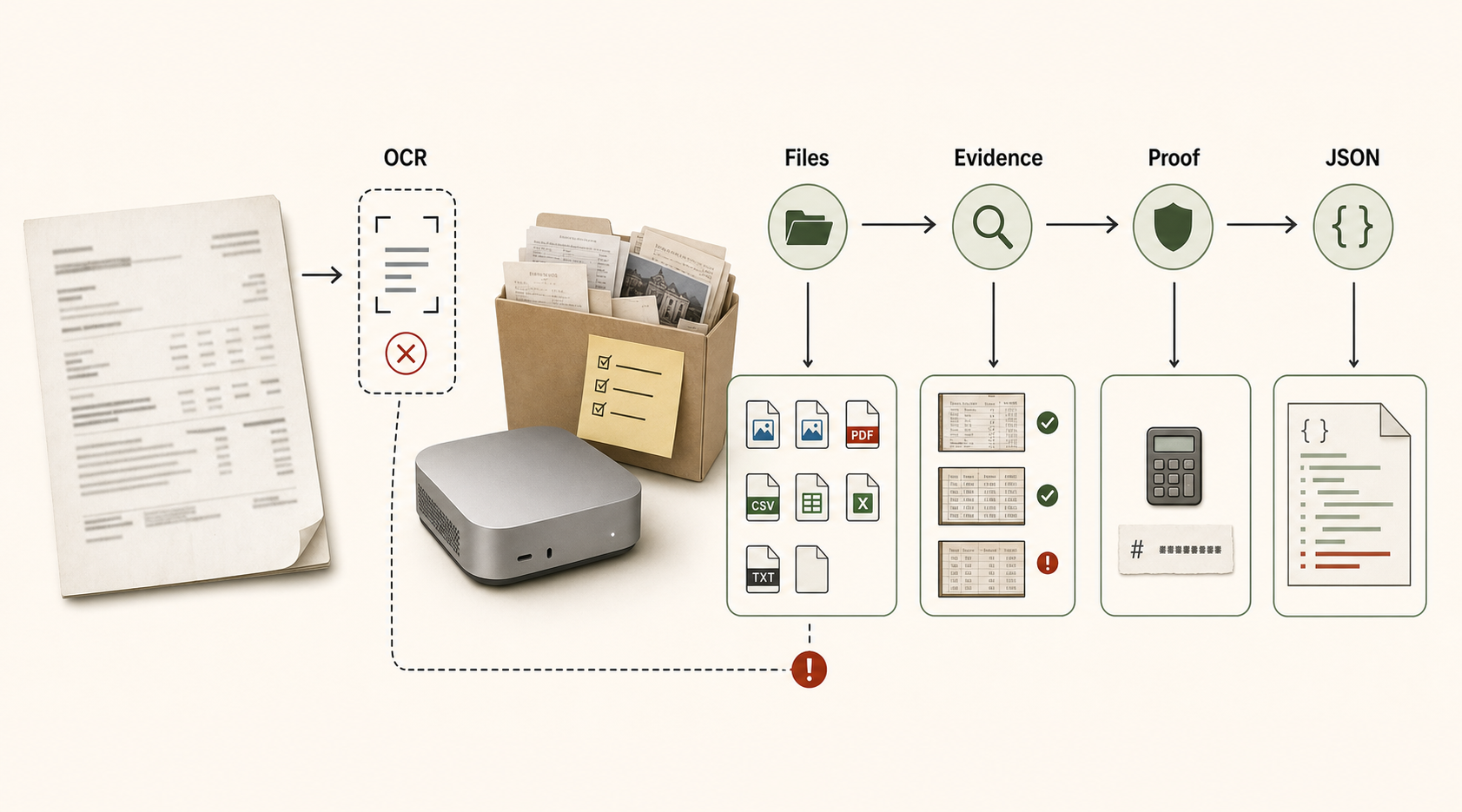
In the paperwork suite, the model sees more than a scan. It may also see a bank export, a vendor master file, a purchase order, a list of old invoices, a note from accounting, and a folder full of attachments with unhelpful names.
Some files are relevant. Some are stale. Some look official but should be ignored. That is where the benchmark starts to matter.
The actual task is a small workflow
The Paperwork Trial asks the model to audit synthetic invoice folders and write an exact audit_result.json.
The Paperwork Workflow cases go further. The model has to inspect a messy intake folder, identify active source files, preserve protected inputs, create intermediate artifacts, and write the final result in the expected place.
That is not OCR. It is a constrained local workflow.
The model has to decide whether the document is an invoice, quote, or credit note. It has to match payments against bank exports. It has to notice inactive vendors, missing purchase orders, duplicate risks, revised attachments, and old files that should not be used.
Then it has to cite evidence and finish the output contract. Many models can do parts of that. Fewer close the case.
The useful failures are boring
The failures worth measuring are not cinematic.
A model reads the total, then misses the duplicate-risk check. It identifies the right vendor, then cites an evidence path that does not exist. It understands the revised attachment, then writes the final JSON in the wrong directory.
It gets the audit facts mostly right, then fails the proof code. Or it produces a helpful explanation instead of the required artifact.
Those are not OCR failures in the narrow sense. They are paperwork failures. They are also the failures that make local automation annoying in real life.
Why the text-only benchmark exists
This is why Local Model Bench also has a Paperwork Text-Only diagnostic.
In that version, the model receives normalized document extracts instead of invoice images. OCR and vision are mostly removed from the problem. If the model still fails, the bottleneck is somewhere else: classification, arithmetic, evidence handling, duplicate-risk logic, instruction following, or final artifact discipline.
That split is important. Can the model read the document? Can it complete the job after the document has been read? Those are different questions.
What this benchmark is really asking
For private desktop work, a local model needs more than recognition.
It needs restraint. Do not touch protected source files.
It needs file judgment. Do not use the old attachment just because it appears first.
It needs artifact discipline. Write the JSON, manifest, proof file, or normalized output exactly where the task asked for it.
And it needs evidence. Not "the invoice says so", but a usable path back to the file or row that supports the warning.
That is a higher bar than OCR. It is also closer to the work people actually want local models to do.
Practical readout
OCR asks whether the model can read the page.
Local Model Bench asks whether it can finish the folder.
The distinction matters because many local models already look impressive on a single scan. The harder question is whether they can survive file choice, reconciliation, evidence, proof, and exact output.
The benchmark is not trying to replace OCR tests. It is testing the work that starts after the OCR demo looks done.