The headline is tempting
A local model beating a stronger reference agent makes for an easy headline. It is also easy to overread. The result does not mean Qwen3.6 27B is generally smarter than Codex, better at software engineering, or better at long multi-file coding tasks.
It means something more specific and more useful: on a narrow text-only paperwork task, a local model produced more exact final artifacts than the Codex reference run. That is enough to be interesting without pretending it proves everything.
What the text-only task removes
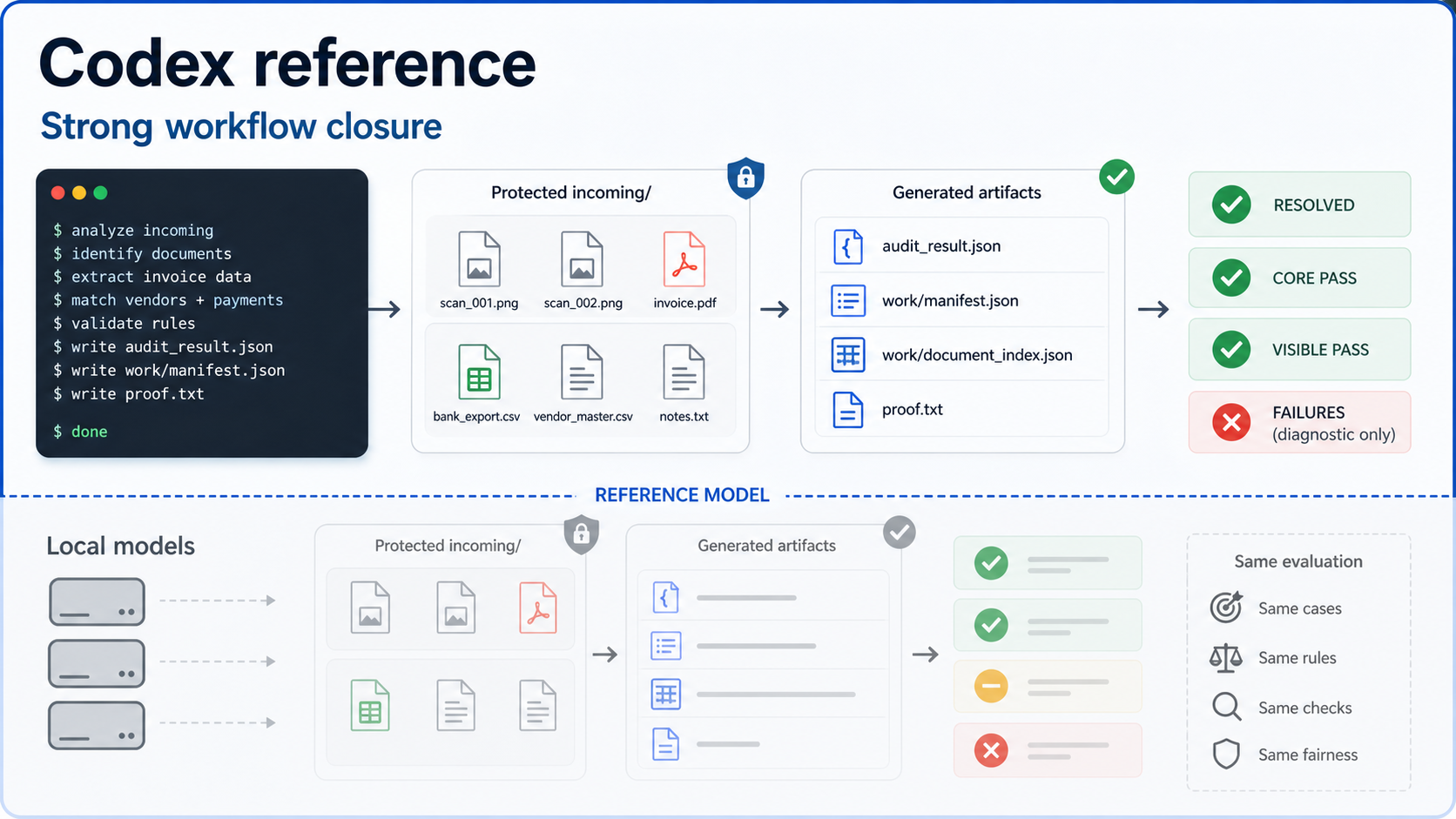
The text-only benchmark removes the hardest image-reading part of the main paperwork suite. Both models receive normalized document extracts instead of raw invoice scans. That levels the field for models that are not being tested as OCR systems.
What remains is the bookkeeping contract: identify the right documents, classify the invoices, compute totals, assign warning codes, produce valid JSON, and close the proof code. The task is small, but it is exact.
Where Codex lost points
Codex did not collapse. It reached core pass on four of five cases. That means the central audit facts were mostly right. The gap appeared in strict resolution: proof codes, warning-code closure, and final artifact exactness.
That is precisely why the benchmark tracks core pass separately. A model can understand the case and still fail the output contract. In this run, Codex looked capable but did not finish enough cases cleanly.
- Codex text-only: 50.0% Practical
- Codex strict resolved: 1/5
- Codex core pass: 4/5
- Qwen3.6 27B text-only: 80.0% Practical
- Qwen3.6 27B strict resolved: 4/5
Why a local model can win a narrow task
Local models do not need to be better at everything to win a constrained task. They only need to be good enough at the exact contract in front of them. If the task is stable, synthetic, and narrow, a direct local model call can outperform a stronger general agent that drifts on closure details.
This is one reason practical local AI remains interesting. The value is not that a desktop model becomes a universal replacement for frontier systems. The value is that a local model may be good enough for a private, repeated workflow where the schema and checks are well-defined.
What this does not prove
The result does not prove that Qwen3.6 27B should replace Codex for coding. It does not prove that local models are broadly better than cloud models. It does not even prove that Qwen3.6 27B will win after the benchmark expands.
It proves that score design matters. If a benchmark rewards exact artifacts rather than persuasive explanations, the ranking can change. That is not a bug. That is the point.
The practical lesson
For private local workflows, the best question is not 'which model is smartest?' The better question is 'which model resolves this repeated job with the least review?' On the text-only paperwork diagnostic, Qwen3.6 27B did that better than the Codex reference run.
That makes the result useful, not absolute. It gives us a baseline for local document work and a warning for agentic systems: final checks, proof codes, and boring output contracts are where confident systems still slip.